So, I'm working on something that requires me to alternate between 2 side-by-side name tables every 8 scanlines (8 scanlines of name table A, 8 scanlines of name table B, then back to A, and so on). Can anyone think of a way to do this that doesn't involve using the MMC3 (or other complex mappers with IRQ functionality) or wasting nearly 100% of the CPU power on timed code?
In an ideal world, DMC IRQs would be enough to time this, but somehow I doubt I could get something stable enough out of that. On the other hand, there is the fact that the window for writing to $2000 is huge, since horizontal scroll changes are buffered until the end of the scanline, so the timing doesn't have to be particularly precise, just enough for the write to happen anywhere in the correct scanlines.
I might end up going with the MMC3, as that'd bring other advantages besides the scanline counter, but I though I'd ask here first to see if anyone could think of something I didn't consider. Thanks.
Is this to get 16x8 attribute zones? If so, you could interleave the data such that you only had to change after every 16 scanlines.
lidnariq wrote:
Is this to get 16x8 attribute zones?
Nope, it's to draw software pixels that are 4 pixels tall, using tiles that are 8 pixels tall.
Quote:
If so, you could interleave the data such that you only had to change after every 16 scanlines
I'm using the same principle, but on tiles rather than on attributes, so I can change nametables every 8 scanlines instead of 4.

tokumaru wrote:
Can anyone think of a way to do this that doesn't involve using the MMC3 (or other complex mappers with IRQ functionality) or wasting nearly 100% of the CPU power on timed code?
The obvious answer is using another mapper with scanline IRQs, such as any VRC mapper, MMC5, FME-7 or develop your game for the Famicom Disk System. I think that's not what you wanted to hear though.
DMC IRQs aren't precise enough for that, and you don't want to waste most of the CPU's time so the only way to go is developing a new hardware mapper capable of this automatically. By re-routing some adress line to CHR-A10 it should be doable easily, but will be havily non-standard and not emulatable.
VRC IRQs are cycle based, rather than true scanline timings, so they might not be quite as good for chaining repeated splits like this.
A restricted subset of MMC3 probably isn't too bad to build these days.
A simple mapper that makes it easy could be great, too. Maybe something like the Punch Out mapper where reading byte 4 of a specific tile you place at the end of the line will trigger a split automatically. New mappers don't seem as big a problem to me as they used to, there's quite a few good actively developed emulators these days that might keep up.
Yeah, for comparison, GTROM was let loose 2015(?), and by may 2017, mesen had full support. fceux r3293 has support for the most important features, and likewise, so does powerpak.
This is because GTROM has become a very popular homebrew mapper.
A mapper that is simple enough to be about as cheap as nrom, unrom, gtrom etc, yet passively interleaves rows from two nametables, would nicely fill a role for any homebrew that seeks a slanted topdown perspective (popular with adventure games, rpgs, action puzzles) or an isometric view.
The example below could be a probably have more liberally constructed maps, including the z axis, better shadow effects, and so on.
Attachment:
File comment: doodle i made some time ago for the "maybe sometime" pile of ideas.
 filtered.bmp [ 847.55 KiB | Viewed 2759 times ]
filtered.bmp [ 847.55 KiB | Viewed 2759 times ]
.
I'm not well-read on the cartridge port side, but am i right to believe all it'd take is cutting and jumpwiring some traces? alternatively from a design perspective, inculde a three-point jumper/solder bridge to be able to reroute the behaviour.
rainwarrior wrote:
New mappers don't seem as big a problem to me as they used to, there's quite a few good actively developed emulators these days that might keep up.
FrankenGraphics wrote:
Yeah, for comparison, GTROM was let loose 2015(?), and by may 2017, mesen had full support. fceux r3293 has support for the most important features, and likewise, so does powerpak.
This is because GTROM has become a very popular homebrew mapper.
It really all depends on whether you want emulator support primarily for development/test, vs if you plan to release a rom that you want the majority of people to be able to use. The average joe (who possibly plays emulated games on their phone or raspberry pi) won't have access to an emulator that supports GTROM or other new mappers for quite a while, I imagine.
That's not an issue if you primarily plan to release on cartridge-only, or if you don't care to target the larger rom-consuming community. But if you do, then using a new mapper will still limit your audience for quite a while. (and that's not even considering folks who have clones like the Retron 5, who may miss out when you use a custom mapper)
(I'm not trying to argue that a new mapper is a bad idea, heck, I'm using GTROM in the game I'm making. Just that there are potential downsides even IF you can find some emulator support)
For testing or playing under emulator - use MMC3
For doing physical cartridges - use 4020 counter and count 8 * 8 rising edges of PPU A12
good points gauauu, it then becomes a question of how you'd intend to spread the software. Unless it's a proof of concept for a small crowd.
-an mmc3 type of thing is available for everybody as a freely shared ROM.
-a cartridge release on a typical homebrew Kickstarter scale of 200-500 units (upper figure is rare) would benefit financially from having a cheaper mapper than an mmc3. Even if physical mmc3 games are doable like this, you need to reach a higher threshold to break even.
FrankenGraphics wrote:
A mapper that is simple enough to be about as cheap as nrom, unrom, gtrom etc, yet passively interleaves rows from two nametables, would nicely fill a role for any homebrew that seeks a slanted topdown perspective (popular with adventure games, rpgs, action puzzles) or an isometric view.
[...]
I'm not well-read on the cartridge port side, but am i right to believe all it'd take is cutting and jumpwiring some traces? alternatively from a design perspective, inculde a three-point jumper/solder bridge to be able to reroute the behaviour.
Yes, one could easily add cartridge hardware—in fact, just a 74'161—to automatically interleave namatables every 4 rows.
Specifically: latch PPU A2..0 on reads from pattern tables (i.e. 74'161.CK ← PPU/RD and 74'161.LE ← PPUA13). Because of how the PPU's fetch cadence works, the first fetch will have bogus results—that nametable fetch follows a sprite pattern fetch instead of a background pattern fetch—but that can be concealed with the "mask left 8 pixels" control.
The complicated part is if you ever want to turn it off.
lidnariq, I'm in no way qualified to validate your idea, but it'd be great if it could really be this simple. Would CHR-RAM or 4-screen mirroring interfere with that in any way? I can live without being able to turn it off.
lidnariq wrote:
Specifically: latch PPU A2..0 on reads from pattern tables (i.e. 74'161.CK ← PPU/RD and 74'161.LE ← PPUA13).
OK, I'm trying to make sense of if this: why do I need to latch PPU A2..0, and what do I do with them?
Now that I think of it, couldn't I latch just A2 (the bit that selects the top or bottom 4 rows of a tile) on pattern table reads, and use that as the lower name table selection bit? I'm not very good with hardware, so sorry if I'm way off, but my thinking is that whenever the top half of a tile is read, the left name table will be selected, and whenever the bottom half of a tile is read, the right name table will be selected. Does that make any sense?
Didn't you want automatic nametable switching? How are you thinking 4-screen would interact with that?
CHR-RAM wouldn't interfere.
This is approximately the same idea as mapper 96, or the initial drafts of what
HardWareMan did for his InviteNES flashcart. (Unfortunately, his images expired from whatever host they're on)
—
tokumaru wrote:
couldn't I latch just A2 (the bit that selects the top or bottom 4 rows of a tile) on pattern table reads, and use that as the lower name table selection bit?
No, that's exactly correct. I don't know if there's a cheaper way to get "latch one bit when signal is low and another signal rises" than just a single 74'161, though.
lidnariq wrote:
Didn't you want automatic nametable switching? How are you thinking 4-screen would interact with that?
I don't know... I still want to have control over which pair of name tables to use with the automatic switching (i.e. the top 2 or the bottom 2), so I imagine I'd need another latch for that, right?
What I'm not sure is how I'd use the 2 name table selection bits to control the VRAM chip in the cartridge... They'd have to be used only on name table reads, so that'd be when A13 is high, right?
Quote:
CHR-RAM wouldn't interfere.
OK.
Quote:
This is approximately the same idea as mapper 96, or the initial drafts of what
HardWareMan did for his InviteNES flashcart.
Oh, I didn't get much of that back then, but I see it now.
Quote:
No, that's exactly correct. I don't know if there's a cheaper way to get "latch one bit when signal is low and another signal rises" than just a single 74'161, though.
Awesome. I guess this is still all a bit too experimental for my taste, though... It's mainly the lack of support for this in emulators and Flash carts that bothers me. I could build a socketed cartridge for development, but that'd be far from ideal.
EDIT: Wait, I don't need to latch the vertical name table selection bit, A11 can go through unmodified, but I do have to decide whether to drive the horizontal bit with the latched value (reads when A13 is high) or let A10 just go through (all other cases). Would that make 2 sets of 2 name tables possible?
tokumaru wrote:
lidnariq wrote:
Didn't you want automatic nametable switching? How are you thinking 4-screen would interact with that?
I don't know... I still want to have control over which pair of name tables to use with the automatic switching (i.e. the top 2 or the bottom 2), so I imagine I'd need another latch for that, right?
What I'm not sure is how I'd use the 2 name table selection bits to control the VRAM chip in the cartridge... They'd have to be used only on name table reads, so that'd be when A13 is high, right?
Think about it like this...
A nametable is 1K of memory. The PPU natively provides two controls (PPU A10 and A11) to address 4 nametables (but only pre-provides enough memory for 2). But you can keep on adding more address lines as long as you have enough memory for it.
For example:
"Horizontal mirroring" connects PPUA11 to CIRAMA10.
AOROM connects an output from the latch to CIRAMA10.
GTROM connects PPUA10, PPUA11, and an output from the latch (via extra hardware) to CHRRAMA10, CHRRAMA11, and CHRRAMA14.
All of these are ways to allocate some number of chunks of 1K of memory to the region seen by the PPU.
So there's a bunch of options, depending on just how much RAM you're talking about. If you wanted something like GTROM, but instead of having two planes of 4 nametables controlled by the CPU latch, you could instead just connect the output of the PPU address latch to the same extra hardware and end up with a single 64x120 "stout tile" display, corresponding to 512x480 pixels.
Alternatively, you could also get away with just using the 2K of RAM inside the NES; then you'd have a single 32x60 "stout tile" display, corresponding to 256x240 pixels.
Quote:
It's mainly the lack of support for this in emulators
Looking quickly at Mesen's source (especially OekaKids and MMC2), I bet adding support would be really easy.
It just occurred me that maybe a lua script can simulate this automatic switching in emulators... I might give this a try.
tokumaru wrote:
It just occurred me that maybe a lua script can simulate this automatic switching in emulators... I might give this a try.
Something like this should work for Mesen:
Code:
local mirroringReg = 0xA000
local horizontalMirroring = 1
local verticalMirroring = 0
local lastAddr = 0
function switchNametables(addr)
if (addr & 0x3FF) < 0x3C0 then --ignore attribute fetches
if (lastAddr & 0x20) ~= (addr & 0x20) then
if addr & 0x20 == 0 then
emu.write(mirroringReg, horizontalMirroring, emu.memType.cpu)
else
emu.write(mirroringReg, verticalMirroring, emu.memType.cpu)
end
end
lastAddr = addr
end
end
emu.addMemoryCallback(switchNametables, emu.memCallbackType.ppuRead, 0x2000, 0x2FFF)
Obviously this is just a test (for MMC3) but you should be able to tweak it easily enough for any other mapper.
Result:
Attachment:
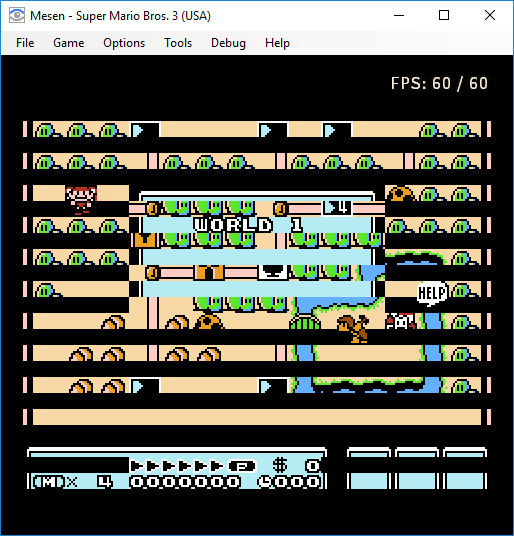 smb3.png [ 20.81 KiB | Viewed 2252 times ]
smb3.png [ 20.81 KiB | Viewed 2252 times ]
Thanks for the example, Sour!
If you can admit lost area at the top of the screen and loosing perhaps some CPU time, you could probably pull it off with some DMC IRQ trickery combined with roughly timed code ? Triggering IRQs each 8 lines and even each 4 lines is possible with this method after all. The problem is that it's extremely though to control where those IRQs will trigger, also they won't trigger exactly each 8 and 4 lines but only a non-integer # of scanlines slightly shorter than that. The fact that high timing precision for $2000 writes can be taken advantage of to some extent so perhaps something smart is possible.
Very likely you'll have to have a time-compensating loop on each IRQ whose waiting time will be pre-calculated and variable each time, and you'll lose up to 25% of CPU time doing this.
I've done some work with DMC IRQs to try to have arbitrary splits -- I wouldn't recommend trying this for this many scanlines. Remember that IRQs happen on their own clock, starting up to 432 cycles after you trigger them. Depending on the alignment you could waste a lot of time on many of the scanlines.
All this talk about custom mappers and such is great, but in the end, that's way too experimental for me. Too many places where things could go wrong, from the mapper design and prototyping, to modifying emulators and even manufacturing carts if the game ever gets completed.
I'm contemplating doing something I also consider crazy, but crazy at the software level, which makes me much more confident. I'll try dividing the rendering logic in my raycaster into fixed-time chunks of 4 or 8 scanlines (whatever works best), so I can alternate name tables in software in between logic chunks. Then, after the 3D view, comes the bottom of the screen with the status bar and such, which doesn't need timed code, so the game/object logic can run during that time.
Dividing the ray casting and texture scaling into constant-timed chunks sounds like a bit of a challenge, but they are extremely repetitive tasks, so it just might work. I do expect to lose some processing time simply making the best cases take as much time as the worst cases, but I'd also lose a lot of time with other software-only solutions, such as using DMC IRQs or generating all patterns on the fly.
Good luck having code that is even remotely maitainable... But it's what makes the most sense. If you're already loosing a lot of times to render the screen, you don't want to loose any CPU time waiting for synchronization, even if it is just a little. So I think it makes sense, but you want to make sure your rendering algorithm is set is stone and is not going to be changed once you start coding this... because maintaining it will be a complete nightmare.
You could also aim at constant-time rendering, so that the framerate even if slow will be constant. I think it's a good idea. At least you'll be really pushing the system to its limit.
If you needed to develop a new mapper anyway, you might as well have the mapper doing the ray-casting itself, so I agree it's a bad approach.
Bregalad wrote:
If you needed to develop a new mapper anyway, you might as well have the mapper doing the ray-casting itself, so I agree it's a bad approach.
Oh, come on. That's wholly unfair. There's a huge difference between a trivial chunk of discrete logic doing something like the Oeka Kids mapper and a coprocessor.
Bregalad wrote:
Good luck having code that is even remotely maitainable...
Well, it's just the rendering code, so I don't expect it to change at all once it's working and generating proper results.
Quote:
If you're already loosing a lot of times to render the screen, you don't want to loose any CPU time waiting for synchronization, even if it is just a little.
The strategy I plan on using is basically to unroll the tasks and do as much as possible in 4 or 8 scanlines, and then decide whether to continue in the same block or jump to another one. For example, there'll be a block of code that just extends the ray and checks the map for collisions with walls, and this will be used over and over until a wall is found. If there's enough time to test, say, 6 wall boundaries between scroll splits, I'll have to include wait loops for when a wall is found before the 6 checks, so that the block still takes the same amount of time to finish. That could add up to a lot of lost CPU time, unfortunately.
Quote:
but you want to make sure your rendering algorithm is set is stone and is not going to be changed once you start coding this... because maintaining it will be a complete nightmare.
Not much worse than an Atari 2600 kernel, I suppose.
Quote:
You could also aim at constant-time rendering, so that the framerate even if slow will be constant. I think it's a good idea. At least you'll be really pushing the system to its limit.
With the different amounts of distances rays have to travel, the different heights of the walls, and the varying amounts of enemies and their proximity to the player, I think that'd be very hard, and wasteful. I have to believe that these things are going to compensate for each other (e.g. a longer ray that takes more time to cast will result in a smaller wall that takes less time to texture), and design the levels in ways that avoid too much heavy processing in the same spot.
Quote:
If you needed to develop a new mapper anyway, you might as well have the mapper doing the ray-casting itself, so I agree it's a bad approach.
That doesn't sound particularly fun to me. I want to see the NES do all the work, not just have the PPU pump out the pixels.
I've been giving some more thought to this and the constant-timed rendering chunks will end up wasting much more CPU time than I anticipated. Not only will I constantly have to "do nothing" when the task finishes too soon, but I'll also waste lots of time in NTSC if I plan on supporting PAL consoles, since PAL scanlines are shorter. The most sensible thing to do would be to just bite the bullet and go with the MMC3. If I'm doing something complex, there's no shame in using a more complex mapper, and if I insist in chasing crazy alternative solutions I'll probably just be shooting myself in the foot.
Thanks for all the replies. I particularly liked lidnariq's idea of constructing a simple custom mapper, and I even learned a bit more about mapper design from it, so thanks for the suggestion!
tokumaru wrote:
I particularly liked lidnariq's idea of constructing a simple custom mapper, and I even learned a bit more about mapper design from it, so thanks for the suggestion!
I've been occasionally tempted to make a special emulator build that has all these wacky experimental hardware designs. To keep the scope sane, it'd have to be only hardware that uses a small handful of 74xx ICs.
What with Mesen having a useful debugger and running on Linux I might even get around to it.
That'd be really cool! I really like to read/talk about these cool little mapper ideas, but for someone who's not very experienced with hardware, the idea of physically constructing these cartridges to test their viability is a bit daunting. The very few times I tried, things didn't go well. The possibility of simulating these ideas before actually constructing anything sounds great.
The other option is to write an emulator that supports mappers written in WebAssembly or some other intermediate language that can be JIT-recompiled. Someone in the GBDev Discord server discussed making an emulator that supports exactly this.
tepples wrote:
The other option is to write an emulator that supports mappers written in WebAssembly or some other intermediate language that can be JIT-recompiled. Someone in the GBDev Discord server discussed making an emulator that supports exactly this.
I don't think having JIT-compiled mappers is very useful. Mapper development for emulators is easy enough by compiling offline. What lidnariq is proposing (being able to simulate the mapper hardware in an emulator using a predefined set of readily available hardware components) would provide a very simple transition path from simulation to hardware, maybe lowering barrier of entry for people who might be unsure what kind of mapper designs would be feasible on hardware.
Oh, no, sorry, nothing so sophisticated. I was just observing that Mesen definitely gives me enough rope, its mapper descriptions are succinct enough, and it has a highly-useful debugger, such that I could easily manually make the full set of "what if I attach a latch in this weird place" mappers.