Zepper wrote:
Using chkdsk now... ;)
CHKDSK will not fix this problem. All that's going to do is potentially make your situation worse depending on how important the data is on the drive right now. *sighs* The only option you have given this drive's bad condition is to open up an RMA with Seagate and have the product replaced. The enclosure and the drive are
a single product. Seagate, assuming the product is still under warranty (their site can determine this for you), will replace the entire product free of charge.
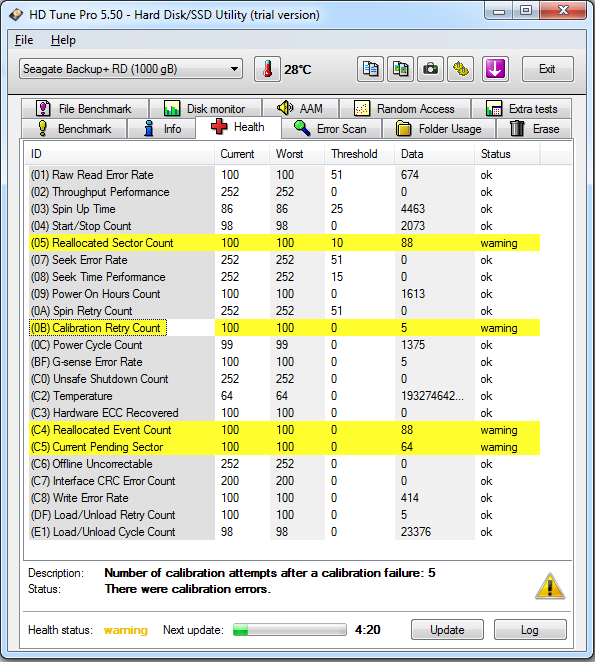
As for the individual attributes that are of concern -- and I'm having to go off of what HD Tune Pro shows rather than smartmontools, so my ability to reliably decode this is somewhat limited -- they are decoded below.
Please ignore the "warning"/yellow labels in HD Tune Pro -- the author of this software does not fully understand that a non-zero value in some attributes DOES NOT indicate trouble (furthers my point about people needing to know how to decode the data properly). Also be aware that
assuming SMART attributes are all zeroed from the factory on new drives is false.
Also be aware that even the descriptions
of SMART attributes on Wikipedia are wrong. For example, attribute 197 says "If an unstable sector is subsequently read successfully, the sector is remapped and this value is decreased" -- that is
completely false for many models of drives (ex. all Western Digital drives I've ever used and analysed, including present-day ones). So you can't entirely trust that either.
Attribute 1 (0x01) -- with Seagate drives sometimes this attribute is vendor-encoded and other times its a mix between a "rate" and a counter. Therefore, sometimes a non-zero value here can indicate repeated re-read attempts done by the drive itself (the storage layer has no idea what's going on under the hood) where eventually the drive is successful in reading data from a physical sector. Whether or not that's the case on this specific model I do not know (I'm not familiar with this exact model).
Attribute 5 (0x05) -- indicates there have been 88 successful LBA remaps during its power-on lifetime. An LBA is simple an arbitrary number that acts as a pointer to a physical sector on the disk. Disks made in the past 15-20 years use LBA addressing, thus computer accesses data on a drive via an LBA, not a sector (the OS has no concept what physical sector an LBA points to). So what this counter indicates is that there have been 88 events where an LBA points to a spare sector. More on what that actually "means" down below.
Attribute 9 (0x09) -- indicates the number of power-on hours of the drive. On this model, the counter represents hours, thus 1613 hours =~ roughly 67 days of power-on time. This is a fairly new, or at least fairly unused drive.
Attribute 11 (0x0B) -- indicates the drive has had 5 physical recalibration events during its power-on lifetime. Because this is a portable drive, this is more common/more likely than if it was a drive in a stationary system (ex. desktop). However, I would classify 5 full recalibrations during such a short power-on lifetime is an indicator of something physical going on within the drive. It may have been dropped, jostled or incorrectly assembled at the factory (despite QC/QA). All are possibilities, and all are speculative.
Attribute 191 (0xBF) -- indicates the drive has had 5 shock events during its power-on lifetime. This number correlates with Attribute 11 above. "Shock events", or "G-shock", are indicators that the drive itself was dropped or jostled while it was on. (The drive cannot count these type of events when power is off). One of the problem with portable drives is that their G-shock sensors are
extremely sensitive; I've seen these attributes increment on 2.5" Western Digital drives in laptops simply by someone picking the laptop and putting it back down on a flat desk. They're very sensitive. However, these kind of physical movements can in fact jostle the actuator arm and heads to the point where misalignment can take place. Remember: hard disk R/W heads [url]are literally floating a few
nanometres above the surface of the platters[/url]. Whether or not these physical events caused damage to the platters, inducing LBA remaps, is impossible for me to tell (especially with HD Tune Pro; I might have a better idea with smartmontools).
Attribute 194 (0xC2) -- this value is vendor-encoded on Seagate drives and cannot be decoded using HD Tune Pro. I believe smartmontools can decode this. This value should be ignored for this analysis.
Attribute 195 (0xC3) -- most Seagate drives have this attribute as non-zero and is vendor-encoded. This is the first time I have seen a Seagate drive show a 0 value for this attribute. I'm noting it here because it's a good indicator of how each drive model and firmware version change in behaviour vs. comparative models. Normally this attribute indicates a count or possibly a rate of how often sector-level ECC has to be used to autocorrect data read from a sector (each actual sector on a hard disk contains an ECC region, alongside data and some metadata).
Attribute 196 (0xC4) -- Relates to attribute 5, indicating that there were 88 reallocation event counts. Note that this number does not necessarily have to equal that of attribute 5; this is an "event count", which does not necessarily guarantee an actual LBA remap. HD Tune Pro mislabels this attribute, sadly.
Attribute 197 (0xC5) -- indicates there are 64 "suspect" LBAs there are pending analysis. This explanation is long, so get some coffee or whatever.
During a read operation, a drive can have problems reading data from an LBA (which points to a physical sector); dust on the platters, head misalignment, spindle motor problems, actuator arm is slightly off, the list is endless. The drive internally (OS has no idea) will attempt to re-read the LBA an arbitrary number of times (varies per firmware implementation), and once reaching a retry threshold, will mark the LBA "suspect" and move on.
"Suspect" means the LBA can no longer be read by anything -- including the OS. You'll receive an I/O error when attempting to read from it.
It does not mean the physical sector the LBA points to is bad/unusable, it just means that at that moment in time the drive could not read data from that LBA (and the drive will no longer let anything read that LBA).
The data at that LBA is effectively lost. You cannot get that data back, aside from one possibility: taking the drive to a data recovery company (specifically one who does physical data recovery, as in moves the platters to a donor drive or takes physical repair action). This requires you have issued
absolutely NO WRITES to the drive. It's very hard to guarantee that too, because Windows writes crap to a disk under the hood all the time, you have no idea what it's doing. And I'll explain why the "DO NOT WRITE TO THE DRIVE!" matters:
A "suspect" LBA is only re-analysed (to determine if the sector the LBA points to is actually good/usable or not, or if the LBA should be mapped to a spare sector)
on a write. So in some cases, yes, you can literally write to all the "suspect" LBAs on a drive and the number shown in attribute 197 will decrease as each sector at that LBA is deemed usable. Of course because you're writing data to the LBA, if successful, the data you just wrote will (naturally) overwrite whatever was there, but at least there wasn't an LBA remap. (Also in the case of an LBA remap or no LBA remap, attribute 196 will not decrement, hence why it's an "event counter" rather than a "remap counter").
A common technique I use to "test" drives in states where there are a very low (say 1 or 2) number of "suspect" LBAs is to simply write zeros to the LBAs which cannot be read (figuring out which LBA numbers to use is something the drive itself can do, believe it or not -- a SMART selective test, and on some drives a SMART short or SMART long test, can be used to get LBA numbers per results in the SMART self-test log -- HD Tune Pro does not support this, and it's a tedious/complex operation I won't describe here, but I use it regularly to do data recovery for people).
Now you see why ANY writes to the drive can potentially mean data loss if you are in fact wanting data recovery, particularly if the write hits a "suspect" LBA.
I'll use this opportunity to point something out: LBA numbers shown in OSes/within software (particularly on Windows) do not always map 1:1 with the LBA numbers used by a drive. They SHOULD map 1:1, but I have personally experienced many occasions where the OS has claimed LBA xyz is unreadable when in fact the LBA is some arbitrary number lower or higher than what the OS claims. I believe this is caused by storage drivers (ex. SATA/AHCI drivers) which use NCQ to report the incorrect LBA number (i.e. a driver bug). This is why I prefer to use the drive's own analysis tools (at the SMART level) to give me numbers.
And one more thing, more relevant I think: determining what file on a filesystem uses what LBA number is extremely painful on Windows (on Linux and FreeBSD it's a bit easier, but it depends on the filesystem (ext3 vs. reiserfs vs. UFS/FFS vs. ZFS)). Windows is a complete disk about this. There are speculations that
fsutil can provide this on Vista or 7 or 8 (not XP), but the few times I've used it the numbers its given are wrong / don't match reality. So I think it might actually be giving NTFS cluster offset/number, which
IS NOT the same as an LBA.
The best thing to do to find out what files are impacted by "suspect" LBAs is to use a file copy utility (not a filesystem or partition or disk copy utility). Files read which return I/O errors are obviously impacted, and the utility should obviously give you the filename.
I hope this explains why using verification utilities when writing data to the drive are now questionable -- meaning: sure, you can write a 300MByte file to a drive successfully, but it doesn't mean you're necessarily going to successfully read all that data back (yes, it's true: a write can succeed where a read of the data LBA fails. My above explanation about "suspect" LBAs and how to reanalyse them should explain why/how that's possible).
Attribute 198 (0xC6) -- indicates how many failed LBA remaps there have been. This is particularly common if a drive has undergone extensive LBA remapping and has run out of spare sectors (uncommon but does happen, especially on 4K / 4096-byte sector drives). This value is 0 so that's good, it just means there haven't been any failed remaps.
Attribute 200 (0xC8) -- write version of attribute 1. Won't go into this for the same reasons as describe in attribute 1.
Attribute 223 (0xDF) and attribute 225 (0xE1) -- I'm tired and am opting out of explaining these... sorry.
There is also one more situation that people have speculated about:
bit rot. I've personally nor professionally ever encountered this (usually I can explain sudden checksum failures when using ZFS for example; I can correlate them to SATA or SCSI or SAS events), but I do believe it's a strong possibility given how magnetic media works. But
do not be inclined to believe SSDs are somehow better in this regard -- SSDs have their own sets of major problems that MHDDs don't. I don't want to get into a talk about that, but search Slashdot for "SSD" sometime and read the analysis done by some folks. Also, don't trust things you read on "enthusiast" websites (i.e. gamer-fuelled hardware review sites) -- these guys often have no idea what the fuck they're talking about, and that includes occasionally dudes like Anand Lal Shampi (guy who runs Anandtech -- note the guy started the site when he was 14 years old... yeah, great, a 14 year old doing hardware reviews... I know he isn't 14 now, duh, but still...). Proper reviews and analysis have to be done by actual engineers; "enthusiast" sites often "talk tech" but have no fucking idea how something
actually works under the hood. When it comes to hard disks, particularly IDE/PATA/ATA/SATA/AHCI, I'm one of the few who does. (What I don't fully understand are the physical characteristics, because I'm not a hardware engineer)
I'm certain this very long explanation will induce a billion questions of all sorts (I can see Tepples writing up some enormous 200-page inline response), just know that I can't/won't really answer a lot of them because drives are very complex and it's a tedious process for me to explain it all with text/typing. I've done software-level data recovery for a long time (I speak/read ATA protocol and have worked on some of the FreeBSD ATA and AHCI subsystem drivers, although not at very deep levels) so that's where I get the education on this -- and a lot of people who do the same thing do it wrong/badly because they don't understand
how drives work (or the fact that different models and vendors of drives behave differently; ex. WD drives do not behave the same with regards to many of the above as Seagate drives (I have more experience with WD drives)).
Anyway... the reason you're getting back anomalies during verifications after writing data to the drive is because while your writes worked fine, reading the same LBAs you just wrote to fail / are marked "suspect" by the drive.
So, long story short: don't bother copying anything to that drive any longer. Any data you have on it right now which you want to keep, copy off to another drive/somewhere else (and any I/O errors when reading that file means that you should ignore that file -- it's been lost, I hope you have other backups of it :) ), then do an RMA with Seagate to get a replacement product. That's the simple answer. There is no point in trying to "save" this drive given the behaviour/description of the problem -- it will perpetually be like this forever.
If you want to see the (probably hundreds by now?) examples of me assisting in drive problems, Google "koitsu dslreports drive" or "koitsu dslreport disk" and sift through them all. I even
tell stories of data recovery, with data if you're into that sort of thing.