I know that a lot of people say this that is not possible.
Is it possible? I could SWEAR that I have seen some NES emulators achieve it. DirectDraw is now dead so I can't use WaitForVerticalBlank anymore.
Are there any work-arounds for this?
WaitForVerticalBlank didn't eliminate tearing in windows anyway, so there's no need to lament its passing. It was more or less the same as what Present can do (except Present has many more options).
I've heard stories about getting it to work on Vista or Windows 7, but they always involved the user doing weird things to his graphics drivers. I don't know of any way to guarantee it via the game software.
My advice is to just use the standard API for double buffering with vsync, make sure it works in Fullscreen, and then forget about it for windowed mode-- at that point it's in the user's hands.
I could be wrong though; the situation may have changed in Windows 7, but if it has I haven't seen any documentation on it yet.
Direct3D 9+ has an InVBlank RenderStatus value that can be used, but it won't work on Vista/7 unless you disable Aero, and it won't work on 8 period. Forget about it with OpenGL =(
Lots of bad drivers though where they report Vblank start too far in, so you get permanent tearing near the top of the screen, should the window happen to be there.
Lastly, you can look into the DWM APIs. I haven't tried it because it's Vista+ only.
XNA did vsync in windowed mode using only calls to present.
But if you're really trying to avoid using Direct3D, you could use timers, polling what scanline is currently being displayed, Sleep(1), and timeBeginPeriod.
Dwedit wrote:
XNA did vsync in windowed mode using only calls to present.
But if you're really trying to avoid using Direct3D, you could use timers, polling what scanline is currently being displayed, Sleep(1), and timeBeginPeriod.
How can I poll scanlines without Directdraw? Btw I'm not avoiding Direct3D far from it in fact.
Looks like you use "IDirect3DDevice9::GetRasterStatus" or something like that.
But figuring out how to use Present seems like the way to go.
So let me get this straight: "Present" is accented on the second syllable (pre-ZENT the verb, not PREZ-ent the adjective), and it's related to what GL calls "swapping buffers". Am I correct?
Yes, Present() is a function, and is intended in the verb sense, as most function names tend to be. Under most setups it is flipping the double buffer and displaying it to the screen.
I wouldn't try to do anything based on scanlines; scanlines are not generally relevant to modern display programming techniques, and I seriously doubt you can get reliable/useful results from GetRasterStatus, though it might be useful if you're targetting a very specific hardware setup.
You don't really have direct access to the buffer the hardware displays to the screen in windowed mode, so it really doesn't matter how you time your own stuff; the OS updates that on its own terms, you're rendering to a different buffer that gets copied onto the real screen buffer by the OS. That timing can be indirectly affected by what you do, and it might seem to give a consistent lack or tearing under certain circumstances, but it probably won't work in others. I'm not aware of any robust API for doing a proper swap during vblank, other than taking control of the screen via fullscreen mode.
When I tested out a minimal XNA program (one that rapidly flashes the screen red and blue every frame), I was seeing a hiccup (dropped frame) every few seconds, at other times, it was smooth and tear-free. Sometimes it ran for 11 seconds without a hiccup, other times it hiccuped after 2 seconds.
That's what direct3d Present(...) will do.
Windowed mode is supposed to allow many applications share the screen space, and this may be the reason why there has never been an API for vsync the windowed display. Consider this:
1. For the majority of applications, tearing is not a problem. The only applications which require monolithic screen updates are things like animation, video, and games (and these kinds of applications tend to offer fullscreen modes, where vsync is not a problem).
2. Waiting for vsync slows down your application. It cannot continue updating until the vsync has passed. For a program that does not require vsync, this would reduce program performance with no benefit. So, the default behaviour for most applications must be not to vsync.
3. In fullscreen mode, one application has exclusive use of the screen. Your application has the option to wait for vsync, but none of the backround applications need to, and will run unimpeded. Exclusivity makes the problem of providing vsync very simple.
4. In windowed mode, you have a lot more requirements to fulfil. You don't want to slow down programs that don't need to vsync, but it's not very easy to do this. Most windowed programs are written in such a way that their screen updates need to be posted immediately before the program can proceed; forcing the OS to update its screen only at vsync, and then giving one window the ability to pre-empt that update means that all other programs are occasionally going to be waiting on the vsynced window. I dunno, it's possible to do I think, but in the context of operating system design I don't think it's an easy problem to solve. Anything I can think of at the moment carries a lot of complications.
I dunno, maybe there is a simple/elegant way to implement windowed vsync in an OS without hindering other programs, but if there is it escapes me. I suspect the implementers of Windows have felt that it's just more trouble than it's worth, and that fullscreen mode already addresses the problem of tearing sufficiently.
rainwarrior wrote:
1. For the majority of applications, tearing is not a problem. The only applications which require monolithic screen updates are things like animation, video, and games (and these kinds of applications tend to offer fullscreen modes, where vsync is not a problem).
Which says what about in-webpage video (e.g. YouTube) and in-webpage games (whether Flash or HTML5)?
Quote:
2. Waiting for vsync slows down your application. It cannot continue updating until the vsync has passed.
Ideally, other programs running on the system can continue updating.
Quote:
For a program that does not require vsync, this would reduce program performance with no benefit.
So does waiting for a mouse click or a keypress.
Quote:
3. In fullscreen mode, one application has exclusive use of the screen.
One of the screens or all of the screens? What if I have a walkthrough video running full-screen on one monitor and a game running full-screen on another, and these monitors have different refresh rates? But I guess multiple monitors on a home PC itself is an edge case that's so uncommon it's economically a rounding error.
Quote:
Your application has the option to wait for vsync, but none of the backround applications need to, and will run unimpeded.
If PC vsync were an interrupt as opposed to a spinlock, they would have run unimpeded anyway.
Quote:
Most windowed programs are written in such a way that their screen updates need to be posted immediately before the program can proceed; forcing the OS to update its screen only at vsync, and then giving one window the ability to pre-empt that update means that all other programs are occasionally going to be waiting on the vsynced window.
When a program calls "wait for next event", and there isn't a timer event due in the next 20 ms, then the program expects to wait.
tepples wrote:
Which says what about in-webpage video (e.g. YouTube) and in-webpage games (whether Flash or HTML5)?
YouTube and a lot of other web video applications appropriately offer fullscreen modes. Flash has a fullscreen mode as part of its API, though not a lot of in-browser games use it because it does not allow use of the keyboard at the same time. I dunno if HTML5 addresses this. As a whole, people are quite used to the choppiness and tearing of video/animation in a browser window. It's ugly, but it's ubiquitous. Do you think there's a general understanding that watching video on a television is a smoother experience than watching it in a web browser?
tepples wrote:
Ideally, other programs running on the system can continue updating.
That's what I said, isn't it? Actually what I'm saying is that it's critical that they do so.
tepples wrote:
So does waiting for a mouse click or a keypress.
...and? I'm talking about the performance of programs that want to continue running. Programs that have halted themselves waiting on user input aren't a performance concern.
tepples wrote:
One of the screens or all of the screens?
This is a good question. I do not know how well (or if) vsync works with multiple monitors. It's something I've never had to deal with. I think multiple monitor PC systems are not uncommon, but I don't think most game developers want to make that a requirement to play their game.
tepples wrote:
If PC vsync were an interrupt as opposed to a spinlock, they would have run unimpeded anyway.
Yes, effective use of an interrupt is an essential part of implementing this. This is why it's good to use something like D3D's Present instead of rolling your own, since this is its normal behaviour.
tepples wrote:
When a program calls "wait for next event", and there isn't a timer event due in the next 20 ms, then the program expects to wait.
The vsynced program expects to wait for a vsync, but other programs should run unimpeded. My point was that attempting to provide vsync for just windows that request it would most likely infringe on the performance of the other running programs because of how the shared screen resource must be managed. Programs can survive being forced to wait now and then, that's expected by the programmer, but for an operating system it may be a bad policy to allow a feature like vsync to cause systematic waiting that reduces performance across the board.
Smooth animation is apparently not Windows' highest priority when it's trying to provide multiple running programs access to the screen, and I think this is probably the right thing to do in the general case.
rainwarrior wrote:
tepples wrote:
So does waiting for a mouse click or a keypress.
...and? I'm talking about the performance of programs that want to continue running. Programs that have halted themselves waiting on user input aren't a performance concern.
A mouse click is an event. A key press is an event. Data received on a socket is an event. The completion of a frame on a given monitor is an event. Fundamentally, these events can be waited for with the same API call, which might end up resembling select() from POSIX. Perhaps such an event might result from completion of Present().
Quote:
tepples wrote:
When a program calls "wait for next event", and there isn't a timer event due in the next 20 ms, then the program expects to wait.
The vsynced program expects to wait for a vsync, but other programs should run unimpeded. My point was that attempting to provide vsync for just windows that request it would most likely infringe on the performance of the other running programs because of how the shared screen resource must be managed.
Even in a modern composited environment? If a repaint handler hasn't finished, just use the texture saved when the repaint handler began. It's sort of like triple buffering.
If you design your operating system's use of video around being able to provide vsync, and thus create an API that requires that all programs that need to update the screen can be buffered and have a reasonable expectation of interacting with vsync timing, then it'd probably be relatively easy to provide vsync in windowed applications. I don't really think this is the case with Windows. It is the case with Direct3D, and other APIs developed around games or animation specifically, but the Windows API itself offers a lot of ways to get things done.
Programs that double buffer are generally already set up to operate in a way that is germane to vsync, and a common API for double buffering is really all that is needed. However, while double buffering is almost always a requirement for animation programs (even when vsync isn't expected), this is not the case at all for general UI programming. You could wrap everything in double buffers, but when you start wrapping single buffered behaviour in double buffers you end up doing a lot of duplicating actions, blitting unnecessary data, etc., and there are a lot of programming patterns sensible in single buffering that would become pathological performance cases when shoehorned into a double buffering system.
Anyhow, I'm no expert on the inner workings of Windows' implementation. I'm just speculating that the design decision not to provide a mechanism for vsync in windowed applications may have been a sensible choice to make.
You can always try rendering to video overlays instead of the regular back-buffer. These basically provide an independent swapping chain on top of the regular display, typically used for video playback by media players.
There's plenty of downsides though. They're optional, have only one channel, use hardware-dependent YUV formats, are unsupported on Vista, use a new interface on Windows 7, won't work across multiple-monitors, etc.
If you're dead-set on avoiding tearing at all costs then they're probably the way to go. Just be sure to have a fallback.
Or, you know, just pray your users have Aero enabled and a properly configured system..
You can skip my post, but coming from an upbringing on systems that had instantaneous scrolling and animation (NES, Amiga) the lagginess & shearing that still seems unavoidable in Windows makes me... (searches for the "puke" smiley)
It's not unavoidable at all if you go to fullscreen mode and put your game thread at higher priority.
The reason windows is laggy and sheary in windowed mode is because you're doing 10 things at once. Your NES couldn't do that at all. Stuff that ran on the Amiga workbench had
plenty of lag and flicker.
I did several things at once on a 1999 laptop with one 0.333 GHz P6-class core. Clock speeds, number of cores, and instructions per clock have increased since then. Shouldn't a 2 GHz quad core i7 (6x clock, 4x parallelism, 2x IPC) be able to run more than 10 things?
Various issues with some of the ideas in this discussion:
"VSync should just be an interrupt!": Ok, who gets it, and in what order? If it's a single core machine, at best everything that asked to be notified will find out about it, in some order. You have no idea what other programs are trying to do, and the OS can't really enforce things. Likely outcome: you tear anyways, because your particular timeslice doesn't land until halfway down the screen.
"Scrolling and large movements look terrible, they didn't on my amiga!": Drawing under windows is inherently tied to the WM_PAINT message, that gets delivered to each window that needs it. For it to show up, first the message goes into the application's message queue, which it's main thread has to pump occasionally. Windows has no control over when that happens, and applications are terrible about doing that in a timely fashion. When you get the usual "Blah (Not Responding)" that's the application not pumping it's message loop. If it isn't pumped, the message doesn't go to the window, and no draw commands happen.
Once the message is delivered, windows calls the window proc, and usually that just switches on the message type. WM_PAINT messages have some additional requirements, they have to wrap their draws with BeginPaint() and EndPaint(), which validates the part of the screen they're asked to repaint. The drawing for most things is generally done with GDI, and has a terrible track record for hardware acceleration. Additionally, applications can catch and override any of the messages windows sends down, including the ones involved in painting the window frame, title bar, etc.
On top of all that, a lot of apps do not bother trying to paint just the part that was invalidated, and redraw their entire window no matter what. Usually they start with a clear, to make sure things look right, and may take a particularly long time to iterate through redrawing all their controls. You've probably seen the crap that shows up in parts of a window that get uncovered when that app isn't responding to WM_PAINT for some reason. Apps that have a more active update approach (emulators, games, anything that's doing particularly intensive video playback, etc) may update an offscreen buffer, and blit it over in WM_PAINT, but that isn't necessarily guaranteed to happen at any particular time.
Further complicating that are situations like dragging, or hitting menus, etc. Sometimes people write horrible message loops that stall the rest of the application while the user is interacting with that stuff. Whether you drag windows or outlines is under user control, if it's outlines, you won't get any WM_PAINT messages anyways.
Lastly, there's just a ton of data to move around some times. A naive redraw may redraw every pixel in the window 2-3 times, between clearing, and excessive amounts of text or transparent junk. A 1024x768 window at 32bb is ~4M of noncontiguous data in the framebuffer. 1920x1080 is ~8.3M
tl;dr: GUIs are Hard.
VSync should just be a bit going from low to high like on the NES. Yes I know that all kinds of programs might wait for it to go high and then all want a piece of the action at the same time but it would still be a nice feature especially if you could via the Windows API change which program(s) get the highest priority.
ReaperSMS wrote:
Various issues with some of the ideas in this discussion:
"Scrolling and large movements look terrible, they didn't on my amiga!": Drawing under windows is inherently tied to the WM_PAINT message, that gets delivered to each window that needs it. For it to show up, first the message goes into the application's message queue, which it's main thread has to pump occasionally. Windows has no control over when that happens, and applications are terrible about doing that in a timely fashion. When you get the usual "Blah (Not Responding)" that's the application not pumping it's message loop. If it isn't pumped, the message doesn't go to the window, and no draw commands happen.
...
On top of all that, a lot of apps do not bother trying to paint just the part that was invalidated, and redraw their entire window no matter what. Usually they start with a clear, to make sure things look right, and may take a particularly long time to iterate through redrawing all their controls. You've probably seen the crap that shows up in parts of a window that get uncovered when that app isn't responding to WM_PAINT for some reason. Apps that have a more active update approach (emulators, games, anything that's doing particularly intensive video playback, etc) may update an offscreen buffer, and blit it over in WM_PAINT, but that isn't necessarily guaranteed to happen at any particular time.
tl;dr: GUIs are Hard.
Rainwarrior: Well, the Amiga in that vid had a clock speed of 7.14 Mhz... so some GUI redraw lag is quite forgivable.
Another thing compounding that, and related to what Reaper said, the default redrawing mode for Amiga windows is "simple" which means everything gets redrawn every time something is moved, resized... There is a "smart" redraw which uses the blitter to store hidden windows in RAM, then blit them to "VRAM" when they are revealed as windows are moved. Dumb programs might also only use the "simple" method.
Hopefully smart Windows programs also use some kind of smart window caching routine and don't tie up the rest of the system too.
But I guess this topic is about window refresh, not redrawing, so ignore my comments...

What if I were to wait for the vblank with a DirectX function and then start a timer and time say 100 frames to get an average. That way could I just wait for my timer to hit 0 and the Blt windowed?
WedNESday wrote:
What if I were to wait for the vblank with a DirectX function and then start a timer and time say 100 frames to get an average. That way could I just wait for my timer to hit 0 and the Blt windowed?
Do you have access to a timer that good? Probably not.
It sounds like it's worth a try. Just keep in mind that the accuracy of timers can vary between different machines.
QueryPerformanceCounter() (
another) with
QueryPerformanceFrequency(). Or possibly
timeGetTime().
Bottom line: if the underlying hardware the OS is being run on lacks decent timecounters (i.e. the HPET implementation is broken or not enabled, ACPI DSDT is wrong, TSC is broken (this would affect a lot more than just QPC though!), or (and god forbid this be the case) the system's TC is the i8254), then too bad. I wouldn't bother trying to cater to those folks either, especially anyone using the i8254.
QueryPerformanceCounter() doesn't give you a way to sleep your thread and be woken up with accurate timing, though. And if you just spin on it, you're wasting CPU time, and the OS will swap you out at some point; could miss your vblank that way?
Bizhawk uses D3D9's D3DPRESENT_INTERVAL_ONE if the user asks for vsync. It seems to work well for me in windowed mode (low CPU usage, stable with 30hz test patterns), but I guess some implementations are better than others.
natt wrote:
QueryPerformanceCounter() doesn't give you a way to sleep your thread and be woken up with accurate timing, though. And if you just spin on it, you're wasting CPU time, and the OS will swap you out at some point; could miss your vblank that way?
Please define "accurate timing". Give me numbers and units. How granular are we talking here? 1ms? 2ms? 10ms? Longer? Without actual numbers it's difficult to say "you're right" or "let me point you to a resource...".
On *IX systems -- I'll use FreeBSD as an example but I know Linux and Solaris have their own implementations as well -- we have
kqueue(2) which allows a userland application a way to tell the kernel to "call back into" the userland application and run code at a set interval (resolution as low as 1ms -- see EVFILT_TIMER).
I'm fairly certain Windows has an equivalent of this;
this article implies such. But in general, as discussed
in this thread there are certain CPU-level features (specifically CPU P-states and EIST) that can add delays to the interval time. There's nothing you can do about that, honestly -- and don't think those necessarily will cause massive amounts of latency (see very last post in that thread; author insisted those features were cause of stuttering, but the issue turned out to be in his code).
Some posts on stackoverflow also indicate that GetTickCount(), preceded by a call to timeBeginPeriod() (to request 1ms resolution), tends to be more accurate. The problem with GetTickCount() is that you do have to spin in a tight loop. Not very ideal. I will admit here that I have not looked at Windows' thread creation API so I don't know what's available WRT that.
But as I understand it, on Windows the best option you have to keep a CPU from being maxxed out while waiting for a thread to fire is Sleep(). And that's discussed
in this thread.
koitsu wrote:
natt wrote:
QueryPerformanceCounter() doesn't give you a way to sleep your thread and be woken up with accurate timing, though. And if you just spin on it, you're wasting CPU time, and the OS will swap you out at some point; could miss your vblank that way?
Please define "accurate timing". Give me numbers and units. How granular are we talking here? 1ms? 2ms? 10ms? Longer? Without actual numbers it's difficult to say "you're right" or "let me point you to a resource...".
Vblank can vary quite a bit from setup to setup, so I'll put some specific numbers on: My nVidia drivers, at 1920x1080@60.00hz, CVT reduced blanking, give a vblank length of 465us. Using DMT only puts that up to 667us. At that resolution and refresh rate, GTF and CVT are out of the range of HDMI single speed (165Mhz), and so are not possible. (I don't think my setup is all that atypical?)
I'm not aware of any capability in MS Windows to time that finely without spinning or involving some particular hardware interrupt that isn't universally available. There are a lot of Windows APIs out there, though.
...but QueryPerformanceCounter() will give you microsecond precision, despite slight bits of overhead (depends on what you're doing. So I'm still not convinced this is a problem. Here's some other information I found, which also contains code:
http://www.geisswerks.com/ryan/FAQS/timing.htmlThe conclusion he reaches at the end of this article is that a combination of the two models should work best. And given what I understand of both of those models, I'm in full agreement. This, to me, is separate from the thread issue -- again, I have little experience/knowledge about Windows' threading model, but Sleep() should do the trick for the most part.
Overall if there is some API that's similar to FreeBSD kqueue(2) that lets the kernel call userland code at set intervals but with
microsecond granularity, that would be ideal. But I guess my point is that PC hardware today, and over the past 5-6 years, all offer HPETs and ACPI timers that are extremely granular. Software can detect ones which aren't, so I'm left wondering where the issue lies, other than "all this is so damn complex!" (with which I completely agree :-) ).
Doesn't the OS allow you to have it blit the entire window on the next frame without any tearing? It seems like very commonly-needed functionality, for anything showing any kind of video. At least on OS X (even back at 10.3, maybe earlier), this was automatic; once you were done with all the window drawing, I believe you just called a function to tell the OS to update it, and it would all occur on the next frame without any visual glitching or half-drawn things appearing.
koitsu wrote:
...but QueryPerformanceCounter() will give you microsecond precision, despite slight bits of overhead (depends on what you're doing. So I'm still not convinced this is a problem. Here's some other information I found, which also contains code:
Good reads all around. Bizhawk actually has a timer throttle that uses a similar basic implementation; QueryPerformanceCounter() with Sleep() for long waits and Yield() for short waits. (I never looked at it until I read these articles, heh.) The CPU usage is quite high compared to D3D9 VSync throttle, and the particular implementation makes no attempt to synchronize anything to VBlank, but otherwise does well enough.
But perhaps I'm letting the original problem get away from me here... When does D3DPRESENT_INTERVAL_ONE not work right? And if the answer is "when crappy drivers!", then is there anything that can be guaranteed to work in such a situation? If all you have is GDI+, you can't guarantee any sort of timing because your paint commits have another dozen layers of sludge to go through before they get to hardware.
blargg wrote:
Doesn't the OS allow you to have it blit the entire window on the next frame without any tearing?
Yes*. With DWM enabled (assuming Vista/7/8), that's the only behavior you'll get in windowed mode. In other words, you can generate 1000 frames per vsync interval, but DWM is only going to output the last completed frame.
* Mostly yes, at least. You're not guaranteed that the update will happen following the next vsync, as DWM can miss/skip frames (if, for example, dwm.exe scheduling is delayed).
I've had no success with this in the past. I always get tearing. I've tried the GetRasterStatus and even many system specific hacks. Nothing was reliable, let alone reliable on other people's systems.
I have not pried into how it works, but in both Windowed and Fullscreen mode the Allegro library gives me no trouble with Vsync; my game runs at 60fps and I do not get tearing when scrolling. Allegro's Vsync does exactly what I would expect, and doesn't seem to eat a lot of CPU waiting for it either; the whole game as it stands now eats 30% of 1 of 8 cores.
I used this super-advanced function after flipping my buffer to the display:
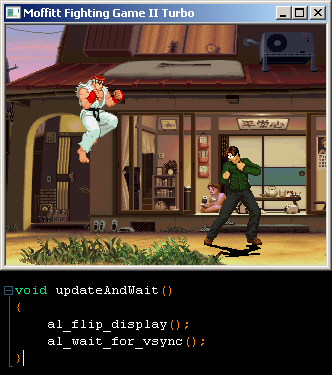
mikejmoffitt if what you say is true/accurate, then windowed vsync is possible. However,
Code:
Status = false;
timeBeginPeriod(1);
while (1)
{
if (lpDD7->GetVerticalBlankStatus(&Status) != DD_OK)
MessageBox(NULL, "GVBS FAIL", "", 0);
if (Status == true)
break;
Sleep(1);
}
timeEndPeriod(1);
StretchBlt()......
Slows the application down to about 20 FPS when windowed which makes it difficult to see if VSYNC is actually working. But even if it did 20FPS is still unacceptable.
Remove the sleep statement. At 60Hz, the vertical blanking interval is only going to be about 1.4ms long. Your app is not guaranteed to be rescheduled in exactly 1ms, so it's possible that you're sleeping right past the vertical blanking period.
Did that and the speed fluctuates quite a lot. Plus it was hard to see if there was vsync but I think it did have it. But of course we had 100% CPU usage on 1 core.
Edit: Speed fluctuates so much it negates whether we even have vsync or not. Anyone know how allegro manages it?
Edit: Just had another thought. Basically Sleep() isn't accurate enough, only the CPU is, so what if we did the following;
1. Use any function DDraw/Allegro/Whatever to wait for a vblank.
2. Start a timer that runs alongside the CPU. Let's say that the CPU has 1000000 cycles per frame.
3. When the timer hits 1000000 cycles Blt and reset the timer.
Code:
while (1)
{
Timer = 0;
Blt();
ProcessFrame();
Sleep(1) <-- Sleep where possible until another Sleep(1) would make Timer go above 1000000
// lets say that for example 99000/1000000 cycles have now passed
temp = 0;
while (temp < 1000)
temp++; // lets just say we know that this will kill the other 1000 off
}
This of course assumes that the CPU and the GPU run at precisely the same frame.
As far as I know, Allegro 5.0 only has D3D and OGL backends for windows; no GDI or DDraw stuff. It's probably just using the builtin D3D Present() mechanism for vsync. For OGL? Possibly one of the swapinterval extensions, or just hoping that the drivers enable OGL vsync by default.
WedNESday wrote:
mikejmoffitt if what you say is true/accurate, then windowed vsync is possible. However,
Code:
Status = false;
timeBeginPeriod(1);
while (1)
{
if (lpDD7->GetVerticalBlankStatus(&Status) != DD_OK)
MessageBox(NULL, "GVBS FAIL", "", 0);
if (Status == true)
break;
Sleep(1);
}
timeEndPeriod(1);
StretchBlt()......
Slows the application down to about 20 FPS when windowed which makes it difficult to see if VSYNC is actually working. But even if it did 20FPS is still unacceptable.
A busy wait loop like that is not the way to do things in windows. Other programs will need to run, so even without the sleep() your application will lose time slices randomly. It will also drive up CPU/power usage entirely unnecessarily. There is a function called WaitForVerticalBlank which is designed for exactly this that should be used instead, if you really do want to wait for the hardware vblank. However, Present() is designed to wait for vsync and put the image on the screen with a timing the OS thinks is appropriate, which is more robust than trying to wait on vblank yourself. At your program's level there is no reliable way to vsync a windowed app; if it can be done, it is the OS's job.
mikejmoffitt wrote:
I have not pried into how it works, but in both Windowed and Fullscreen mode the Allegro library gives me no trouble with Vsync; my game runs at 60fps and I do not get tearing when scrolling. Allegro's Vsync does exactly what I would expect, and doesn't seem to eat a lot of CPU waiting for it either; the whole game as it stands now eats 30% of 1 of 8 cores.
I suspect that getting no tearing in windowed mode is really just a matter of luck with how it happens to be timed on your specific hardware setup. I don't believe there's a secret way to trick Windows into vsynching while windowed. Use the standard API for flipping your double buffer, and let the OS do vsync it if it can. Allegro just uses the standard D3D Present() method for vsynching, and this is what you should normally do.
rainwarrior wrote:
mikejmoffitt wrote:
I have not pried into how it works, but in both Windowed and Fullscreen mode the Allegro library gives me no trouble with Vsync; my game runs at 60fps and I do not get tearing when scrolling. Allegro's Vsync does exactly what I would expect, and doesn't seem to eat a lot of CPU waiting for it either; the whole game as it stands now eats 30% of 1 of 8 cores.
I suspect that getting no tearing in windowed mode is really just a matter of luck with how it happens to be timed on your specific hardware setup. I don't believe there's a secret way to trick Windows into vsynching while windowed. Use the standard API for flipping your double buffer, and let the OS do vsync it if it can. Allegro just uses the standard D3D Present() method for vsynching, and this is what you should normally do.
Of note is that I do not think my hardware (and a lot of modern hardware) does a very good job of reporting Vsync... If I maximize the window to 1920x1200, I get tearing about 32px off the bottom of the screen, but it's consistently in the same spot, not the usual psuedo-random tearing position you would expect. In full-screen mode, there is no tearing.
Fun Fact II Turbo: A few quickie things I've made in Multimedia Fusion 2 with hardware acceleration enabled, whilst maximized but NOT in fullscreen mode do not tear whatsoever. How this was achieved I do not know, but it is interesting to observe.
blargg wrote:
Doesn't the OS allow you to have it blit the entire window on the next frame without any tearing? It seems like very commonly-needed functionality, for anything showing any kind of video. At least on OS X (even back at 10.3, maybe earlier), this was automatic; once you were done with all the window drawing, I believe you just called a function to tell the OS to update it, and it would all occur on the next frame without any visual glitching or half-drawn things appearing.
I don't believe that the core Windows API ever had a way to do this directly (the core API was built around a single-buffered model). However, nowadays (as stated several times before) Direct3D has the Present() API which definitely knows about double buffering, and could potentially do this for the user. It probably can do this for the user in the right situations, but it doesn't in all situations.
The bottom line, I think, is that outside of Fullscreen mode, the ability to vsync is not directly under the program's control. The user's display drivers and the specifics of how they're configured are what really determines whether or not a double buffered Present() will act in a way that prevents tearing. You can try to hack a "windowed vsync" solution in software that seems to work on your system, but ultimately it's not going to work everywhere.
Also, newer APIs from Microsoft, like WPF, tend to just use D3D/Present() under the hood. It really is the way they expect you to do double buffering.
(Edit: sorry if I'm a broken record here.)
blargg wrote:
Doesn't the OS allow you to have it blit the entire window on the next frame without any tearing? It seems like very commonly-needed functionality, for anything showing any kind of video. At least on OS X (even back at 10.3, maybe earlier), this was automatic; once you were done with all the window drawing, I believe you just called a function to tell the OS to update it, and it would all occur on the next frame without any visual glitching or half-drawn things appearing.
I believe Windows does this, starting with Vista. When I upgraded to 7, I left Aero turned on, and all of the emulators I use just automatically stopped tearing without me needing to do anything. So, the problem of vsyncing is probably going to disappear with time.
Indeed, I noticed tearing disappearing when switching to Aero on Vista. Which is a shame, because I like the classic theme

.
Get better video drivers I guess? Windows 7 here, classic theme, nvidia card, and zero glitching or tearing on D3D with present interval one, even with a maximized window.
*Bump*
I have finally got windowed VSYNC working in Windows 7 64-bit, Aero theme.
0% CPU usage. 1% GPU usage. 60 FPS.
I basically use Direct3DCreate9 and use a point list with custom colours to render pixels followed by a call to Present().
If anybody would like the code I'll PM it to them.
WedNESday wrote:
*Bump*
I have finally got windowed VSYNC working in Windows 7 64-bit, Aero theme.
0% CPU usage. 1% GPU usage. 60 FPS.
I basically use Direct3DCreate9 and use a point list with custom colours to render pixels followed by a call to Present().
If anybody would like the code I'll PM it to them.
I am interested.

Due to demand for some code I've decided to post some.
Code:
#include <d3d9.h>
#pragma comment (lib, "d3d9.lib")
D3DPRESENT_PARAMETERS D3DPP;
LPDIRECT3D9 LPD3D9;
LPDIRECT3DDEVICE9 LPD3DD9;
LPDIRECT3DVERTEXBUFFER9 LPD3DVB9;
void * ppbData;
struct SBitmap
{
float x;
float y;
float z;
float rhw;
COLORREF Colour;
} Bitmap[256 * 240];
void Blt()
{
LPD3DD9->BeginScene();
LPD3DVB9->Lock(NULL, NULL, &ppbData, NULL);
memcpy(ppbData, Bitmap, sizeof(SBitmap));
LPD3DVB9->Unlock();
LPD3DD9->SetFVF(D3DFVF_DIFFUSE | D3DFVF_XYZRHW);
LPD3DD9->SetStreamSource(NULL, LPD3DVB9, NULL, sizeof(SBitmap));
LPD3DD9->DrawPrimitive(D3DPT_POINTLIST, NULL, 256 * 240);
LPD3DD9->EndScene();
LPD3DD9->Present(NULL, NULL, NULL, NULL);
}
void CreateBitmap()
{
LPD3D9 = Direct3DCreate9(D3D_SDK_VERSION);
ZeroMemory(&D3DPP, sizeof(D3DPRESENT_PARAMETERS));
D3DPP.hDeviceWindow = hWnd;
D3DPP.PresentationInterval = D3DPRESENT_INTERVAL_ONE;
D3DPP.SwapEffect = D3DSWAPEFFECT_DISCARD;
D3DPP.Windowed = true;
LPD3D9->CreateDevice(D3DADAPTER_DEFAULT, D3DDEVTYPE_HAL, hWnd, D3DCREATE_SOFTWARE_VERTEXPROCESSING, &D3DPP, &LPD3DD9);
LPD3DD9->CreateVertexBuffer(sizeof(SBitmap), NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL);
temp2 = 0;
while (temp2 < 240)
{
temp = 0;
while (temp < 256)
{
Bitmap[(temp2 * 256) + temp].Colour = 0x00000000;
Bitmap[(temp2 * 256) + temp].rhw = 0.0;
Bitmap[(temp2 * 256) + temp].x = (float)256;
Bitmap[(temp2 * 256) + temp].y = (float)240;
Bitmap[(temp2 * 256) + temp].z = 1.0;
temp++;
}
temp2++;
}
}
The NULLs in Present can be changed to suit your needs. The order of the variables in SBitmap cannot be changed.
Bitmap[0].Colour = 0 means edit the first pixel and Bitmap[61439] = 0 means edit the last. That's all you need to do to update the bitmap.
Edit: Improved code.
I really don't understand why this would get any better results than drawing two textured triangles.
thefox wrote:
I really don't understand why this would get any better results than drawing two textured triangles.
From all the code that I read up on regarding using textures the code was about 10x bigger than what is above. Someone even posted their texture D3D10 code for me and it was incredibly longer.
I have done no speed comparison of the two but the above is so damn fast you really wouldn't need any better.
Two questions:
Code:
LPD3DD9->CreateVertexBuffer(sizeof(SBitmap) * 256 * 240, NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL);
Why not
LPD3DD9->CreateVertexBuffer(sizeof(Bitmap), NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL); ?
Code:
Bitmap[(temp2 * 256) + temp].x = (float)256;
Bitmap[(temp2 * 256) + temp].y = (float)240;
Why force-casting when members
x and
y are already
float? The compiler will not throw warnings if you removed the force-cast of
(float).
Politely: you have an awful, awful tendency to force-cast things excessively, dude. Break this habit ASAP, as it WILL bite you.
I would also get rid of that statically-allocated
Bitmap[256*240] nonsense and use
malloc() instead. That's multiple megabytes of crap allocated on the heap which you can't guarantee will actually be available (your program will crash mysteriously as a result). You can handle error conditions with
malloc().
koitsu wrote:
Two questions:
Code:
LPD3DD9->CreateVertexBuffer(sizeof(SBitmap) * 256 * 240, NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL);
Why not
LPD3DD9->CreateVertexBuffer(sizeof(Bitmap), NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL); ?
Code:
Bitmap[(temp2 * 256) + temp].x = (float)256;
Bitmap[(temp2 * 256) + temp].y = (float)240;
Why force-casting when members
x and
y are already
float? The compiler will not throw warnings if you removed the force-cast of
(float).
Politely: you have an awful, awful tendency to force-cast things excessively, dude. Break this habit ASAP, as it WILL bite you.
I would also get rid of that statically-allocated
Bitmap[256*240] nonsense and use
malloc() instead. That's multiple megabytes of crap allocated on the heap which you can't guarantee will actually be available (your program will crash mysteriously as a result). You can handle error conditions with
malloc().
Its a global variable. So its in the data or zero section of the executable. That won't crash a program any more than malloc could fail. Your also talking about 256*240*20 = 1.17mb. If you can't malloc 1.17mb you may have bigger problems.
Also, accessing the global variable may be faster than a pointer dereference. (marginally so in most cases, but still faster.)
Actually koitsu;
1. I use the C++ new keyword instead of Bitmap[256 * 240].
Code:
} *Bitmap;
Bitmap = new SBitmap[BitmapWidth * BitmapHeight];
2. If I don't use (float) then VS gives me a warning about using integers with floats etc.
In fact any force-casting that you see in my code is just there temporarily. What you see above is just an example that wasn't supposed to be too serious.
Just removed the unnecessary 256 * 240 code above. Thanks koitsu.
Also, I don't see anything in that code that specifically guarantees windowed vsync. It may just happen to vsync on your machine by chance only. Asking D3D to vsync windowed doesn't always work reliably unfortunately =/
Zelex wrote:
Also, I don't see anything in that code that specifically guarantees windowed vsync. It may just happen to vsync on your machine by chance only. Asking D3D to vsync windowed doesn't always work reliably unfortunately =/
Well in that case if possible could someone give it a try please. I know that FHorse will at some point.
Zelex wrote:
koitsu wrote:
Two questions:
Code:
LPD3DD9->CreateVertexBuffer(sizeof(SBitmap) * 256 * 240, NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL);
Why not
LPD3DD9->CreateVertexBuffer(sizeof(Bitmap), NULL, D3DFVF_DIFFUSE | D3DFVF_XYZRHW, D3DPOOL_MANAGED, &LPD3DVB9, NULL); ?
Code:
Bitmap[(temp2 * 256) + temp].x = (float)256;
Bitmap[(temp2 * 256) + temp].y = (float)240;
Why force-casting when members
x and
y are already
float? The compiler will not throw warnings if you removed the force-cast of
(float).
Politely: you have an awful, awful tendency to force-cast things excessively, dude. Break this habit ASAP, as it WILL bite you.
I would also get rid of that statically-allocated
Bitmap[256*240] nonsense and use
malloc() instead. That's multiple megabytes of crap allocated on the heap which you can't guarantee will actually be available (your program will crash mysteriously as a result). You can handle error conditions with
malloc().
Its a global variable. So its in the data or zero section of the executable. That won't crash a program any more than malloc could fail.
1) Scope has no bearing on this,
2) It's in one of a series of segments (I don't care to remember which --
.dynsym,
.text,
.rodata,
.data,
.bss, or god knows what else), correct
3) Incorrect. There are two reasons for this:
i) If the size of the buffer exceeds stack size, the program's behaviour is unknown (it varies per OS, and on some OSes the result is undefined). There is really no justification for allocating such large amounts of memory on the stack.
ii) With the "static allocation" method, once the data inside of
Bitmap[] is used, it can never be released back to the OS -- there is no way to
free() it. Ultimately whether or not this matters depends on what the application is doing, naturally, but it's a very bad habit to get into -- instead, just use
malloc() and friends and you'll always be safe, with no negative trade-offs.
I've talked about item #3 at length on the FreeBSD lists as well:
http://lists.freebsd.org/pipermail/free ... 72530.htmlhttp://lists.freebsd.org/pipermail/free ... 72534.htmlhttp://lists.freebsd.org/pipermail/free ... 72545.htmlThere are some ways on OSes to "advise" the VM on what to do with such memory, but they're often not portable.
Zelex wrote:
Your also talking about 256*240*20 = 1.17mb. If you can't malloc 1.17mb you may have bigger problems.
Except that you can handle the situation gracefully if you do the allocation yourself, rather than the user getting a bizarre error from the OS that may not make any sense.
Zelex wrote:
Also, accessing the global variable may be faster than a pointer dereference. (marginally so in most cases, but still faster.)
Again: scope has no bearing here. As for the dereferencing hit -- it's negligible in 98% of the cases out there.
Footnote: for C++ you're supposed to use
new and
delete and all that crap -- sure, whatever works -- I'm used to how shit works under the hood.
wait wait, how does a global variable have anything to do with the size of your stack? Is this some kind of "this is how it works with some compiler on some obscure embedded platform?"
Also global data is allocated by the OS at exe init time. Its not allocated on first use. You may be thinking of a local static variable. For example,
int foo() {
static int bar = 0;
return bar++;
}
bar in this example is allocated at program startup by the OS, it is however only initialized to 0 when foo is first run. (watch out for multi-threading issues)
Zelex wrote:
wait wait, how does a global variable have anything to do with the size of your stack? Is this some kind of "this is how it works with some compiler on some obscure embedded platform?"
Also global data is allocated by the OS at exe init time. Its not allocated on first use. You may be thinking of a local static variable. For example,
int foo() {
static int bar = 0;
return bar++;
}
bar in this example is allocated at program startup by the OS, it is however only initialized to 0 when foo is first run. (watch out for multi-threading issues)
That code does nothing and is mostly irrelevant to the discussion. Are we talking past one another? I'm not sure.
Tell me: what do you think happens when "the global data allocated by the OS at exe init time" fails? What happens when do something like
char buf[1024*1024*32]; (scope doesn't matter) and the allocation by the ELF loader (or the "executable loader") fails? I can tell you what happens: undefined behaviour, based on too many situations/scenarios/variables. Instead, allocate memory during runtime and you can handle this situation elegantly.
Edit: Okay, it looks like scope does matter, at least on *IX systems. With
char buf[1024*1024*32]; declared outside of
main(), the allocation ends up being part of the processes active datasize. If declared inside of
main(), it ends up being part of the processes active stacksize. If inside of a sub-function, the allocation only happens when that function is called and is part of the processes active stacksize. If inside of a sub-function that isn't used, the allocation never happens.
The behaviour if the allocation is too large (exceeds system limits, etc.) is undefined however; on some systems it might segfault right off the bat, but on others it might do god-knows-what or just lock up. The risk isn't worth it -- allocate "large chunks" (see those freebsd.org mailing list threads) dynamically so your program can always start/run and can elegantly handle situations where memory pressure is an issue. You should not depend on the ELF/executable loader to do this for you.
What about creating a BITMAP structure, and then... BITMAP *bmp = malloc( foo ) ?
What about #include <vector>, std::vector<SBitmap> Bitmap(size); ? No new, no delete. When you need a pointer, use the Bitmap.data() method. All methods are inline, so it's as fast as a regular "malloc'ed" array.
… but I think it's enough noise with what Bitmap could have been.
Zepper wrote:
What about creating a BITMAP structure, and then... BITMAP *bmp = malloc( foo ) ?
Sure you can do that. You might need to force-cast the return value from malloc (to
BITMAP *), and you would want to pass the size of the
BITMAP structure to
malloc() (e.g.
malloc(sizeof(BITMAP))). That just allocates enough for one structure, however, so if you want an "array of BITMAPs", you need to allocate (and free) them all yourself.
Jarhmander wrote:
What about #include <vector>, std::vector<SBitmap> Bitmap(size); ? No new, no delete. When you need a pointer, use the Bitmap.data() method. All methods are inline, so it's as fast as a regular "malloc'ed" array.
… but I think it's enough noise with what Bitmap could have been.
I don't do C++. Someone else can talk about that.
koitsu wrote:
The behaviour if the allocation is too large (exceeds system limits, etc.) is undefined however; on some systems it might segfault right off the bat, but on others it might do god-knows-what or just lock up. The risk isn't worth it -- allocate "large chunks" (see those freebsd.org mailing list threads) dynamically so your program can always start/run and can elegantly handle situations where memory pressure is an issue. You should not depend on the ELF/executable loader to do this for you.
Well, actually you can. This thread is about a windows-only application, and this particular error, if I'm not mistaken, will result in a popup that says "out of memory". I'm not sure because it's very rare and hard to trigger (need to open many, many programs to fill up virtual swap space). You actually have to run out of virtual memory space on disk for it to occur.
In this case, I'm not able to trigger it because MSVC limits the maximum size of any static array to 2GB, and also limits the executable + static memory to 2GB.
Windows will very happily run an executable with 2GB of code + static allocations. This will really be perfectly fine for almost any modern operating system with a hard drive (or suitable amount of virtual swap space). I think the advice to avoid doing this is completely wrong. It is not likely to cause any problem on any intended platform. Even if it did cause a problem, most modern operating systems are able to give usable error reporting when a program cannot be allocated enough system memory-- this is a case they can meaningfully detect! We've come a long way since DOS.
Valid reasons not to use the static allocation:
1. the bitmap is only needed temporarily, and you would like to release the memory when the program is doing other things.
2. you're targeting an embedded platform, or something else with very little RAM and no virtual RAM, and no error reporting, so you want to check the allocation for an error manually so you can report it to the user.
3. you want to use an array wrapper class like std::vector to aid debugging with things like bounds checking.
In the given case there's no much reason to do something other than the static allocation. This kind of out-of-memory error is practically impossible on the intended platform, and even if it did happen, the OS should report it properly. Having the programmer check for an error that won't happen and report it to the user is pointless busy-work.
One thing I would recommend about it, though, is using symbolic constants for the bitmap dimension, so that if you ever need to change it you don't accidentally do something like change the loop numbers, but not the bitmap size. The consequences of that mistake could be annoyingly strange/subtle and hard to diagnose/fix.
koitsu wrote:
Tell me: what do you think happens when "the global data allocated by the OS at exe init time" fails? What happens when do something like [a statically allocated array in the tens of MiB] and the allocation by the ELF loader (or the "executable loader") fails? I can tell you what happens: undefined behaviour
What happens when the executable itself fails to load? Unless you're trying to get something running on an embedded or ancient handheld device, the ELF loader or PE loader will cause about 32 MiB of swapping when building a 32 MiB zeroed array. So you can expect that at least half the operating system's system requirements will be available for allocation. Even Android devices tend to come with 1 GB of RAM nowadays, though their OOM killer is far different from that of GNU/Linux because of a desire to avoid swapping.
Anyone has any experience with getting vsync (windowed or otherwise) working on Linux/X11 (and yeah, that's a bit vague, but work with me - think common setups

)? Googled around a bit, and it looks bleak.
"What are you really trying to do?"
SDL provides SDL_Flip()
There's the XDoubleBufferExtension; an example is Xscreensaver's "deluxe" screenhack which uses xdbe_get_backbuffer and XdbeSwapBuffers.
GL provides its own stuff, but I don't have a reference handy.
This will vary so much by application and library it's almost meaningless to ask the generic form.
lidnariq wrote:
"What are you really trying to do?"
SDL provides SDL_Flip()
There's the XDoubleBufferExtension; an example is Xscreensaver's "deluxe" screenhack which uses xdbe_get_backbuffer and XdbeSwapBuffers.
GL provides its own stuff, but I don't have a reference handy.
This will vary so much by application and library it's almost meaningless to ask the generic form.
I'm trying to get a 60 Hz vsynced display (i.e., one without tearing) if supported (with slightly adjusted emulation speed to match). SDL_Flip() does not appear to wait for vertical retrace on Linux, making it equivalent to SDL_UpdateRect().
Can those APIs be made to wait for the vertical retrace? Couldn't find anything at a quick glance.
Just found
https://github.com/chjj/compton/issues/7. The commit it links to seems to use glXWaitVideoSyncSGI().
I guess other refresh rates would be acceptable too, to at least get rid of tearing. Unlikely that you'd be able to muck around with refresh rates in windowed mode anyway, or maybe even fullscreen...
I was under the impression that a compositing desktop would offer applications some way to support windowed mode without tearing, seeing as the compositor itself can see vsync. Perhaps the free desktop really does lack essential features.
This is a fairly goofy way to do it, but: the Xvideo extension does seem to reliably do vsync synchronized page flipping.
lidnariq wrote:
This is a fairly goofy way to do it, but: the Xvideo extension does seem to reliably do vsync synchronized page flipping.
Looks interesting. Seems it can do hardware scaling too.
I wonder what the gotchas might be, since this isn't exactly intended use.
Just read the earlier comments about large static array vs. dynamic allocation (malloc, new, etc.). I didn't notice for me the key reason: bounds checking with a debugger. Dynamic allocations have better support for catching out-of-bounds accesses in debuggers than static arrays, due to the ability of the debugger to exert more control over how the allocation is made so that it has larger padding around it, etc.