I ask it here because I'm pretty sure there is people highly skilled in signal processing.
I'd like to be able to pitch scale an audio sample. In order to do this, some kind of interpolation has to be used. I already know how to use nearest neighboor interpolation, linear interpolation, cubic, and so on.
The problem is that all those interpolation techniques are "impure" on the theoretical viewpoint, as they all allow aliasing.
I think the procedure to do a "theorically perfect" pitch scaling by a factor k > 0 would be the following
1) If up-scaling (k > 1) :
1.1 Low-pass filter the input singal with a relative cutoff of 1/k (where a cutoff of 1 would "map" into a cutoff of fs/2)
1.2 Pick samples from the filtered input using nearest neightboor interpolation
This should work because after step 1.1, the input signal doesn't contains any relative frequencies above 1/k, so it's safe to use nn interpolation without fearing any more aliasing.
2) If down scaling (k < 1) :
2.1 Pick samples from the input using nearest neighboor interpolation
2.2 Low-pass filter the output signal with a relative cutoff of k
This should work because of course the original signal doesn't contain any relative frequencies greater than 1, so anything above this is aliasing, which is supressed on step 2.2
Please tell me if this approach is correct or if I'm completely missing something.
1) Scale the sample (nearest neighbor will do), remember the scale factor
2) Run decimation filter that kills anything above half the sample rate of original sample +/- scale factor.
3) Mix to your buffer, and repeat for another channel.
It is computationally expensive, but it seems to be what my Yamaha SW1000XG is doing in hardware.
It also won't destory the crispness of the original sample which happens with most interpolation methods.
Sorry I don't understand much of what you're saying.
For information I just do this for an update of my BRR sample encoder, where the user is allowed to specify a resample ratio and resampling technique. Curently nearest neighboor, linear, cubic and cosine interpolation are implemented. I'd like to add bandlimited interpolation as it sound it's the "correct" interpolation theoretically.
I'm not doing multichannel nor doing it in real time so it's no problem if it's computationally extensive (up to a certain point of course).
The problem is that the resampling ratio is typically a floating point number, NOT a rational number. Even if the user don't enter a number, the resampling will be affected by looping if this is a looping sample, as it has to loop on a multiple of 16 samples.
You kill all the aliases past the nyquist rate with the decimation filter after scale operation. It does not matter if the scale factor is fractional, it better be for any fine adjustment. As you increase or lower the pitch, the nyquist rate will slide proportionally which is why you remember the scale factor - to know where to start decimation.
The 16 sample loop issue of BRR will greatly limit the scale factors, there's not a whole lot to do about it. Non rational numbers can sound right but it is highly sample dependant, you may end up with just right amount of data and things won't break.
Ok, but my question is the following :
- I assume it's correct to use filtering first and resampling next when upscaling (reducing amount of samples / increasing pitch), and use resampling first then filtering when downscaling (increasing amount of samples / decreasing pitch). Is this correct ?
- Since it appears the resampling algoritm doesn't matter, I might as well use the simpler, faster one : Nearest neighboor. Is this correct ?
- Is there a way to short circuit this opperation (resampling then filter or filter then resample) in a single operation, to save memory usage ?
I guess I could answer 3 by myself by thinking correctly and look at the algorithms, but if there is a well known algorithm that I somehow missed I'd like to hear about it.
The ideal filter is a
sinc filter. It is the precise definition of a filter that removes everything above a particular frequency and nothing else. In practice, you can only estimate it with an
FIR filter implementation.
The IIR formula for the filter is on the wiki page I linked. This is pretty simple, your FIR window should stretch backward and forward in time, with "0" at the centre. To account for the cutoff at the edges (e.g. converting infinite response to finite response) you need to apply a
window function to taper the edges off. A hanning window, for example, is one of the simplest effective ones, which is just a cosine. The wider your FIR window is, the closer your filter will be to the ideal.
Using a FIR filter is pretty simple. Just gather enough samples to fill the window, multiply each by the corresponding entry in the FIR window, sum the result, and that's your new output sample.
Bregalad wrote:
Ok, but my question is the following :
- I assume it's correct to use filtering first and resampling next when upscaling (reducing amount of samples / increasing pitch), and use resampling first then filtering when downscaling (increasing amount of samples / decreasing pitch). Is this correct ?
- Since it appears the resampling algoritm doesn't matter, I might as well use the simpler, faster one : Nearest neighboor. Is this correct ?
When you pre-filter and then resample you will add back all or some of the junk depending on what exactly you are using for the resample operation. Post filtering will remove all that excess regardless what you did before.
Quote:
When you pre-filter and then resample you will add back all or some of the junk depending on what exactly you are using for the resample operation. Post filtering will remove all that excess regardless what you did before.
I don't understand you. When shifting the pitch up, I reduce the number of samples, so I loose information. The information lost actually got aliased. So since it's "merged" with the actual meaningful data in the frequency domain, there's no way I can filter it out after resampling. So this has to be done before.
Also, I know how to use FIR and IIR filter, I just don't know how to use them
in the scope of pitch scaling. Sp far, all pitch scaling methods I did were with interpolation and didn't involve explicit filtering (although I think interpolation is some form of implicit filtering).
Also as far I know IIR has many advantages over FIR :
- Less calculation to be done for a filter of similar quality -> faster
- Simulates an analog filter
- No problem with relying on sample data before the start and after the end of the signal
but that's another topic.
Convolution with a linear-phase FIR filter (that is, anything symmetric in time) can be calculated fast because samples corresponding to the opposite sides of the impulse response can be added up before being multiplied by the filter coefficient. But then if you want fast convolution with a really sharp cutoff, you'll be doing FFT-multiply-IFFT.
Bregalad wrote:
When shifting the pitch up, I reduce the number of samples, so I loose information. The information lost actually got aliased. So since it's "merged" with the actual meaningful data in the frequency domain, there's no way I can filter it out after resampling.
In the situation you're worrying about, you are shifting original frequency content up above the Nyquist frequency of your output stream. You cannot keep that information because there is no way to encode it. Hopefully, you're feeding into an analog system where those now-lost frequencies are imperceptible anyway.
Bregalad wrote:
Also, I know how to use FIR and IIR filter, I just don't know how to use them in the scope of pitch scaling. Sp far, all pitch scaling methods I did were with interpolation and didn't involve explicit filtering (although I think interpolation is some form of implicit filtering).
Also as far I know IIR has many advantages over FIR :
- Less calculation to be done for a filter of similar quality -> faster
- Simulates an analog filter
- No problem with relying on sample data before the start and after the end of the signal
IIR has some serious limitations. It is usually the practical way to implement analog filters. Sinc is not an analog filter, though, and anything you do to reduce its complexity comes at an accuracy cost. It's very hard to build an analog filter that has a sharp cutoff and doesn't introduce unpleasant phase delay; this is actually one of the reasons >44kHz audio has recently become a thing, since the filters required to roll off aliasing are a lot easier to build when you can have a soft cutoff that falls gradually from 22kHz.
To implement the ideal sync filter as IIR, it is the same, computationally, as if your FIR was as wide as the entire waveform stream, i.e. every sample in the output is now a convolution of the sinc function with every sample in the input (N^2 complexity).
Tepples suggested FFT, and it is efficient for large convolutions, but its accuracy (i.e. ability to suppress aliasing) also severely limited by the necessity of windowing. If you make an FFT filter that zeroes all frequencies above the intended nyquist, it is identical to the sinc filter. In practice, though, the aliasing that leaks through because of windowing makes it slightly less effective for resampling than the straight FIR approach, IMO (it's a tradeoff though, depending how wider your FIR is). You could probably do the IIR sinc as a giant FFT that encompasses your entire waveform stream (padded to a power of two, and maybe doubled again to avoid reflections from the other side), and that way you could avoid the windowing issue.
Anyhow, here's how to use the sinc filter FIR to resample:
Downsampling:
At the input samplerate, build a windowed sinc function FIR that looks backward X samples and ahead X samples. This sinc should have a cutoff below the nyquist frequency of the output samplerate. Then, for each sample in the output, multiply sample-by-sample the input with your FIR window and take their sum.
Upsampling:
Resample to the output samplerate using nearest neighbour filtering, or whatever is fast (it doesn't matter, you are about to remove the extra frequencies created). Create a windowed sinc function FIR that has a cutoff below the nyquist frequency of the input samplerate. Apply the FIR to the output.
You can't use nearest-neighbor for selecting samples, as that will introduce artifacts. Just consider the case of a sine wave well below the output Nyquist, and changing pitch very slightly. You'll be taking every input sample and then occasionally skip/double one, clearly not correct. You must use sinc interpolation. Each input sample is multiplied by the sinc function and it's all added together, in continuous time. Then you pick the output samples at the new time positions.
blargg wrote:
You can't use nearest-neighbor for selecting samples, as that will introduce artifacts.
Well, if you have an ideal sinc, all of the artifacts should be removed, but you're right: the sinc filter implementation is only an approximation of an ideal, so the sampling method chosen will likely leak through a bit. Using simple interpolation for the input sample selection might be a good idea.
Quote:
You can't use nearest-neighbor for selecting samples, as that will introduce artifacts. Just consider the case of a sine wave well below the output Nyquist, and changing pitch very slightly. You'll be taking every input sample and then occasionally skip/double one, clearly not correct. You must use sinc interpolation. Each input sample is multiplied by the sinc function and it's all added together, in continuous time. Then you pick the output samples at the new time positions.
I tried writing code from this description but I failed. I see that the filtering is done from the input buffer, but how do you pick output points from the filtered input ? Is what you said specific to upscaling, or is it applicable in both cases.
Anyways, I tried to come up with some (probably wrong/broken) pseudocode to help you guys know what I'm trying to do.
The input is the array called samples[] and the output is called out[], resample is a floating point representation of the resample ratio (>1 = upsample, loose quality, higher pitch, <1 = downsample, lower pitch).
Code:
coef[0] = 1.0;
// Compute FIR coefficients (only do it in a single direction since it's symmetrical anyway)
for(int j=1; j<FIR_QUALITY; ++j)
{
coef[i] = sin(resample*pi*j) / (resample*pi*i);
coef[i] *= i/FIR_QUALITY; // Factulative filter windowing (improves filtering quality)
}
for(int i=0; i<out.length; ++i)
{
//Linear (?!?) interpolation at the output
accumulator = samples[floor(i*resample)] * fract(resample) + samples[ceil(i*resample)] * fract(1.0-resample);
for(int j=0; j<FIR_QUALITY; ++j)
{
if(i-j >= 0)
accumulator += samples[i-j]*coef[j];
if(i+j < out.length)
accumulator += samples[i+j]*coef[j];
}
out[i] = accumulator;
}
It's very hard to make clear code where all the steps are folded into one.
The unambiguous way to do resampling is:
* Upsample. Insert 0s between samples. This will produce overtones; we don't care because of the next step. Using any interpolator more sophisticated than sample-and-hold will just be wasted calculation.
* Lowpass filter. Probably a sinc FIR filter. This filter should have its stop band below the lesser of the two Nyquist frequencies of input and output.
* Downsample. Throw away every Nth sample.
Everything after that is optimization. Folding the last two steps together is the most obvious one, because you can skip some stages of the FIR.
The problem of this upsample/downsample approach is that it only works for rational numbers were the nominator and denominator are relatively small. If I were to resample a 1 minute long sample by, say, 10000/10001, you'd quickly understand that it's going to eat a ridiculous amount of RAM.
Even if RAM were infinite I still want to do it for arbitrary real numbers.
And I'm sorry if my pseudocode is not "clear code", but anyone is free to post something better (in fact I'd really like someone to post something better ^^)
Start with how a sampled signal ideally is converted to analog: each point generates a sinc function centered on it.

In continuous time, several sample points (blue, green, red, cyan, magenta) each contribute their respective sinc function, which adds up to the black waveform:

At each sample point, the amplitude is determined by that sample point alone, since the sinc function has zero crossings at each adjacent sample (see first picture).
So we've just converted a sampled signal to a continuous-time analog version. To sample this at a higher rate, just take the samples from this continuous version. To sample at a lower rate, filter the original signal appropriately, then do the above conversion to continuous time and take the new samples.
For a practical implementation, you can merge the filtering with the sinc function you use, and turn the sinc inside-out so that for a given position at some fraction between input samples, you multiply the nearby input samples by various weights and add the result for the output sample. So you generate a table of these weights for each fractional position you will be using, then run through and apply them. e.g. if you were halving the sampling rate, you'd only need two sets of weights: one for even samples, another for odd samples. If the output rate falls all over the fraction, you might take equal spacings then interpolate the weights.
Quote:
So you generate a table of these weights for each fractional position you will be using, then run through and apply them.
In the Super NES DSP, the Gaussian interpolation stage immediately after BRR decoding does pretty much exactly this. It has 256 sets of four weights, one for each 1/256 fractional position. (Half of those sets are reflected.) See "4-Point Gaussian Interpolation" in
fullsnes for the details.
1- You don't need to load the entire sample at the same time. You only need to keep in memory a length equal to the FIR length.
2- All I'm saying is "do it the stupid way first" so that you can get a proof of concept. Then you can optimize it.
3- You cannot upsample by a non-integral amount. It either involves another stage of filtering followed by downsampling, or smart-ass math that will produce harmonics blended down in the passband; this isn't avoidable. Here's some spectrograms that illustrate my point:
Attachment:
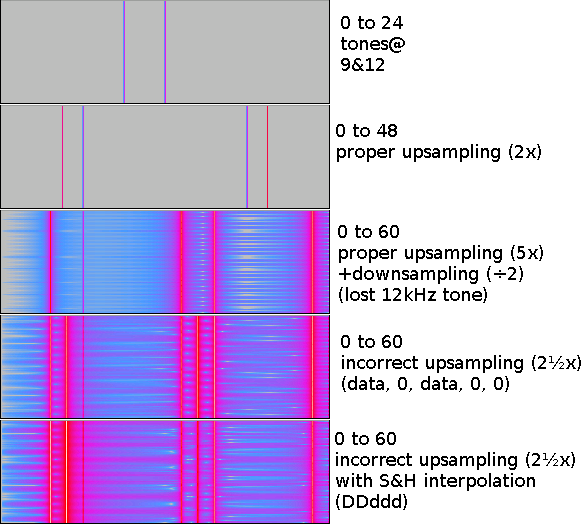 spectrograms2.png [ 13.33 KiB | Viewed 3019 times ]
spectrograms2.png [ 13.33 KiB | Viewed 3019 times ]
The tones on the 60kHz spectrograms are: 9, 12, 15, 33, 36, 39, and 57kHz. All the resultant files were generated from the first row, which was a 48kHz audio file with tones at 9 and 12 kHz.
You can see the noise, and you can see the incorrect signal inserted in the pass band at 15 kHz.
lidnariq wrote:
2- All I'm saying is "do it the stupid way first" so that you can get a proof of concept. Then you can optimize it.
Seconded. Explore with this and keep this around even once you start to optimize. This is an invaluable reference implementation.
tepples wrote:
Quote:
So you generate a table of these weights for each fractional position you will be using, then run through and apply them.
In the Super NES DSP, the Gaussian interpolation stage immediately after BRR decoding does pretty much exactly this. It has 256 sets of four weights, one for each 1/256 fractional position. (Half of those sets are reflected.) See "4-Point Gaussian Interpolation" in
fullsnes for the details.
However because it varies the resampling ratio, you still get aliasing because to do it properly you must change the filtering when you change the ratio.
Thanks Blargg, I now understood the concept of "sinc interpolation" and in fact it's surprisingly simple.
Now I see that the anti-aliasing filtering has basically nothing to do with the interpolation itself. In fact I could automatically test if resample is smaller than 1 and activate antialiasing prefiltering when this is the case, no matter which interpolation method is choosen.
So the signal processing pipeline could look like this :
When downsampling
Original samplerate -> Nearest neighboor interpolation -> Final samplerate
Original samplerate -> Linear interpolation -> Final samplerate
Original samplerate -> (etc...) -> Final samplerate
Original samplerate -> Sinc interpolation -> Final samplerate
When upsampling
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> Nearest neighboor interpolation -> Final samplerate
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> Linear interpolation -> Final samplerate
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> etc... -> Final samplerate
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> Sinc interpolation -> Final samplerate
However only the sinc actually produces the "theorically correct" result. Other results while theroically incorrect might as well be useful in practice though (for instance, Cubic interpolation produces much crisper sounds which sounds better)
The problem is that two sincs are potentially involved (one for the filtering, one for interpolation). From what you'd say it sounds like it could be optimized but I didn't understand at all yet. I'll just try and see if I can see any optimisation by myself. Since one sinc has a period of the original samplerate, and the other sinc has a period determined by the resampling ratio, it doesn't sound like they would bleed well, though.
Cubic interpolation can be interpreted as a windowed sinc. If I sat down with a computer algebra system, I could construct a plausible window function that, when multiplied by sinc, gives the impulse response of Catmull-Rom cubic spline interpolation.
You don't actually want to use nearest neighbor interpolation when upsampling.
1- It makes any subsequent filtering harder, because you don't get all these 0s that you would otherwise be able to optimize out later
2- It's equivalent to "proper" upsampling followed by a boxcar lowpass, which AFAICT is basically the worst kind.
3- Better to explicitly keep the images you want when you design your filter than to take the random crap a boxcar gives you.
These all (mostly) hold for all other interpolators, too. Obviously #2 varies by interpolator choice. (e.g. linear interpolation is convolution by an isosceles triangle)
In any case, the reason you only need one filter in the end is because the upsample-filter-filter-downsample process allows you to combine the two filters, H(jΩ) = G(F(jΩ))
Bregalad wrote:
When upsampling
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> Nearest neighboor interpolation -> Final samplerate
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> Linear interpolation -> Final samplerate
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> etc... -> Final samplerate
Original samplerate -> Antialiasing prefilter -> Prefiltered signal -> Sinc interpolation -> Final samplerate
Nearest neighbor is like using a box impulse response (rather than sinc). Each sample point is expanded half a period in either direction, so you get a stair-step version in continuous time. This box impulse response introduces higher harmonics (because a stair-step waveform has really high harmonics), and thus expands the spectrum above the Nyquist limit. So you get aliasing when using this form of interpolation.
So any interpolation method that introduces higher harmonics will add aliasing. The lower the magnitude of the harmonics, the less aliasing. Sinc adds none.
I think I understand what you mean. I can filter digially the input so that it doesn't contain any harmonics greater than the desired frequency (in our case half of the new sample rate), but this is only valid if the interpolation doesn't create high frequencies again.
If you use nearest neighboor (or anything else than sinc), even if the input signal is lowpass filtered, it is represented by a continus time equivalent which has harmonics above what we want.
I think I will now be able to code this, thank you very buch Blargg, your explainations were very helpful.
I don't know if it is appropriate, but you can look at the sinc resampler I coded and gave to FamiTracker: download FamiTracker's sources, and look in Source/resampler. There's only 5 files. I admit it has rather terse comments. The resampler works obviously, and should be fairly fast, as the FIR only calculates the output samples without actually decimating or upsampling (I think it is called a polyphase FIR resampler). The resampler uses a 'sinc' object, which you can make as big as you want, but it'll increase processing time and memory usage. This resampler can use fractional and irrational ratios, but avoid very small or very big ratios (like, abs(log10(ratio)) > 2) as it will use a ridiculously big amount of RAM. To further reduce aliasing at the expense of some bandwidth, you can even lower the corner frequency.
Now I got the filter working with the following portion of C code :
Code:
[...]
case 'b': // Bandlimited interpolation
// Antialisaing pre-filtering
if(ratio > 1.0)
{
signed short *samples2 = malloc(2 * samples_length);
if(!samples2)
{
printf("Error : can't allocate 'nuf memory.\n");
exit(1);
}
// Apply low-pass filter of cutoff 1/ratio
for(int j=0; j<samples_length; ++j)
{
double acc = 0.0;
for(int k=j-8; k<=j+8; ++k)
{
if(k>=0 && k < samples_length)
acc += samples[k]*sinc((j-k)/ratio);
}
samples2[j] = (short)acc;
}
free(samples);
samples = samples2;
}
// Actual resampling using sinc interpolation
for(int i=0; i<out_length; ++i)
{
double a = i*ratio;
double acc = 0.0;
// for(int j=0; j<samples_length; ++j) // No windowing (N^2 complexity :( )
for(int j=(int)a-8; j<=(int)a+8; ++j) // Cut windowing with 9 coefficients (N complexity :) )
if(j>=0 && j < samples_length)
acc += samples[j]*sinc(a-j);
out[i] = (short)acc;
}
break;
[...]
Works great, I tested it with the song "Slam shuffle" from FF6 which is famous for having a lot of trebbles, and it seems to cut the aliasing properly enough so it's inaudible.
However several problems remains, namely, I have to manually shut down the volume a lot or else I get saturation all arround (the filter is also amplifying the signal apparently) and I'd like to merge both FIR filtering steps into a single step.
It will probably not be very hard to do those improvements.
I think I know the 'why' of you 'gain' problem: when you filter your signal (in your if (ratio > 1.0)) your signal is convoluted with a sinc function of height '1' (that is, sinc(0) == 1, if your sinc function is behaving normally), which is not correct, because as the cutoff frequency gets lower, your filtered signal will get more and more boost. The reason is simple: your sinc should have a height of 1/ratio, so it does not have a gain different of 1 at all cutoff frequencies.
Think of it this way: suppose you want to filter a signal with a rectangular window 4 samples long, but you want unity gain. You know intuitively that all of your coefficients should be ¼, so it sums up to 1. You know that the value of this sum is the DC gain of your filter (trivial; it is like directly measuring the DC response of your filter!). The same apply to your sinc filter: it should sum up to 1, when broken up into coefficients.
So, unless I overlooked something, changing acc += samples[k]*sinc((j-k)/ratio); to acc += samples[k]*sinc((j-k)/ratio) * 1./ratio; should correct the gain problem.
Thanks, I fixed that much easily. I'd have bet it was something like that.
Finally I didn't merge both filtering steps into one but who cares. This is too complicated as the second filtering stages depends on the fractional part of "a" only, which is different for every sample, while the first part depends on the resampling ratio, which of course don't change. The second part also is not symetric, so the trick tepples mentioned doesn't apply.
The new version of BRRTools including this will be released tomorrow.
Bregalad wrote:
Thanks, I fixed that much easily. I'd have bet it was something like that.
You're welcome.
Bregalad wrote:
Finally I didn't merge both filtering steps into one but who cares. This is too complicated as the second filtering stages depends on the fractional part of "a" only, which is different for every sample, while the first part depends on the resampling ratio, which of course don't change.
That's not as hard as you may think. Interpolation works as if you were "walking" on your original sample, with steps smaller than 1. You calculate via convolution with a sinc the values in-between the original samples. When you downsample it's almost the same thing, except you use steps higher than 1 in your original sample, and
steps smaller than 1 in your sinc function (steps of 1/ratio specifically) . This has the effect of broadening the sinc window, which mean lowering of the cutoff frequency (mind the gain problem here too!).