I just bought a PowerPak, and my little cousin has been using it to test his SMB1 level/graphics/music hack.
My block game works perfectly on every modern emu I've tried it on (fceuxd sp, nintendulator, nestopia). On my NES, it works with two problems. First is that pieces occasionally appear to spawn one cell to the right after a 4 line clear due to the recently discovered interaction between DPCM and the controller clock signal. (That's fixable by reading each controller twice and using the previous frame's keypresses if they don't match.) But I didn't expect the other problem: the fourth block of the next piece flickers. The flicker happens more often when the player tries to do something like move or turn the piece, and it gets much worse once both players have joined. But commercial games don't flicker any more than they do on the emulator or on authentic Game Paks. I've posted my cc65 source code; can anybody tell me where to start debugging to look for differences between NES and emulator behavior? Or is this a known defect in the PowerPak, and I need a ReproPak and a Willem programmer to get perfect behavior?
I do not own a PowerPak so this will be more a personal comment on the subject.
I think there are good chances that your educated guess is right. The powerpak in it own is a nice tool but we should not forget that it's technically an emulator running on the real hardware. So the chance of errors are higher. Or it could be that now the powerPak is showing you something that the emulators didn't.
Don't get me wrong, I'm not saying that the PowerPak is crap or something like that. I think it a nice "geek" gadget for testing some game that you want to play again, now playing some nsf and fds files. But for home brew, it may have some limitation (just look at the MMC5 mapper for example).
In the end you may have to test it on a dev-cart to be able to confirm your issue. I guess your game is an nrom (didn't check the code yet, will check later) so maybe some people in the community may be able to test it for you. I may make a NROM cart soon so if I can find the time I may be able to confirm it.
Edit:
I tried to make a quick hack and convert your game to a MMC3 CHR-RAM, the only dev-cart I have at the moment. It works well on emulators but not on the hardware. I guess I must have done an error in the bank switching code again. I guess I'm too tired. I will try to make it work another day.
Edit2:
It was annoying me that I could not make it work on my dev-cart. My mistake is that I put by accident the code for banking in the banks that needs to be banked (duh).
Test results: If I play 2 players at the same time, the blocks at the top flickers. They seems to flickers more when you move the joystick. I don't think the MMC3 could have any impact on the test results.
Conclusion: The Powerpak seems to reacts like the real hardware. The emulators doesn't. Now on how to fix it... I don't know but at least you can do all your test with your powerpak (if you look at the bright side of things).
If you want the mmc3 version I can post it back but it's just a quick and dirty hack: I'm sure you could do it anytime since you know more than me about the nes

The extent of the flicker changed from one run to the next. (This means the flicker might depend on the phase of the moon^W CPU and PPU clocks upon power-up.)
Strange #2: Holding Select changed the flicker pattern due to the way controller reading and autorepeat were coupled. So I decided to rewrite the controller reading code to fix the DPCM glitch. Right then, the flicker in 1-player mode disappeared entirely, and the flicker in 2-player mode became less distracting. But some flicker remains, and I wish I had someone to help me find what's causing it.
Uploaded version 0.31
tepples wrote:
The extent of the flicker changed from one run to the next. (This means the flicker might depend on the phase of the moon^W CPU and PPU clocks upon power-up.)
That's a nice comment
But you may not be wrong in a way: something external (PowerPak) could cause the difference. Maybe I should try to test it more on my dev-cart to see if I can reproduce the same behavior. I just need you to give some example on how different the flickers were from one run to the other.
tepples wrote:
Strange #2: Holding Select changed the flicker pattern due to the way controller reading and autorepeat were coupled. So I decided to rewrite the controller reading code to fix the DPCM glitch. Right then, the flicker in 1-player mode disappeared entirely, and the flicker in 2-player mode became less distracting. But some flicker remains, and I wish I had someone to help me find what's causing it.
In my case, using both joystick at the same time changed the extend of the flickers. Not using them and the flickers where few. So it could be related to some code near the joystick reading.
Once I can find time (it's not easy with a very young child) I will try to use your new code and test it back on my dev-cart to see how much different it is. If you don't mind, instead of making "a new branch",I would like to insert in your project a few extra line so I can compile easily for MMC3 CHR-RAM and you could merge it after. I guess it could be made so it can be compiled for a NROM or MMC3 very easily.
tepples wrote:
The extent of the flicker changed from one run to the next. (This means the flicker might depend on the phase of the moon^W CPU and PPU clocks upon power-up.)
Don't have any answers, but I ran v0.30 on an NROM eprom board and saw the same thing. Flicker rate changes between power cycles and changes with button input. Might be helpful to know which sprite number that is that's having problems and which sprite numbers are fine. At least you now know its not just your NES, and not the PowerPak
Well, I don't quite understand the technical stuff with the controller reads/DPCM glitches, but it seems that your problem only happens when blocks are moved or buttons are pressed, right? Perhaps try artificial button presses with no actual player interaction. What I mean by that is have AI move and turn blocks randomly to see if the glitch is still there, with no reading/writing to the controller registers. If it is, you can be pretty sure that the problem doesn't lie in reading the controller. If the flickering stops, you can be pretty sure the problem lies in reading the controller. That could greatly narrow down where the problem lies. Sorry if that doesn't help.
bunnyboy wrote:
At least you now know its not just your NES, and not the PowerPak
Great to hear. So we can focus now on scanning the code only.
I recompiled the new code and tested it on my dev-cart.
Like you mentioned, first player mode flickers are gone. As for 2 players mode, they seems to happens only when the 2 players at the same time have a block at the top. But since I had to test it alone, it was a little bit harder to have good test results. Were you able to have more flickers in other conditions?
I couldn't really scan the code yet but the impression is like more than 8 sprites are on the same line, making flickers in your sprite rotation routine? Does the next block + the one you're moving are sprites? When it started to flicker, it give the impression of an overlay block and the flicker was going down at the same time the player's block was moving downward, disappearing one scan line at a time. Once the player block was not over the next block, the flicker was gone.
I'm still new to nes programming but I will try to scan the code and see if I can find anything. Debugging is always good for improving your experience anyway
Banshaku wrote:
I recompiled the new code and tested it on my dev-cart.
Like you mentioned, first player mode flickers are gone. As for 2 players mode, they seems to happens only when the 2 players at the same time have a block at the top. But since I had to test it alone, it was a little bit harder to have good test results. Were you able to have more flickers in other conditions?
On my PowerPak, I sometimes get flicker in one player's next piece even once both players' falling pieces are near the bottom.
There are ordinarily 17 active sprites at any time:
- sprite 0 used to turn the screen off 10 lines before the vblank NMI
- 4 sprites for player 1's falling piece
- 4 sprites for player 2's falling piece
- 4 sprites for player 1's next piece
- 4 sprites for player 2's next piece
Ordinarily, the falling pieces should never interfere with each other because there are four for one player and four for the other, and neither should the next pieces when they're at the top. But when we have two next pieces and one falling piece near the top, one of the next pieces might flicker. So if player 1's falling piece is lower on the playfield than player 2's, it draws player 1's next piece first; otherwise, it draws player 2's first. This way, the falling piece is more likely to cover up any sprite dropouts in the next piece.
Quote:
When it started to flicker, it give the impression of an overlay block and the flicker was going down at the same time the player's block was moving downward, disappearing one scan line at a time. Once the player block was not over the next block, the flicker was gone.
That's how it shows up on the PC-based emulators, and occasionally, I can get it to show up that stable on the PowerPak. But sometimes, the PowerPak has more flicker.
I could start by putting in some code to hide the "overlay block" problem somewhat.
I have a few questions regarding what you mentioned. Of course my questions are more from a beginner's perspective but it could point out things (or maybe not) that we may have not think about.
You said that there is only 17 sprites at the same time on the screen. Ok, I can see that but what about the 47 that are not in used at the moment? Could they have an impact on your next block if they're not initialized properly?
Second question, wouldn't it be possible to put the next block in the background instead of a sprite? I guess one of the reason it was not done must be because of palette limitation and/or the problem that you can only update it when the screen is off but I still want to know why we cannot do that.
I will try to scan your code tonight (if my kid let me...) to learn what is going on at the moment. I will try to see if I can reproduce the other flicker with my dev-cart when both block are almost on the same scanline but closer to the bottom.
Edit:
I did a quick debug session on a break and in the SPR memory there was not more than 3/4 sprites per line. There was 17 of them. After 17, 3 of them with extra data but located at $F0. All of the rest where located at $F0 with 0 for the data. So sprites memory seems fine.
Hmmm.. Could be the wait for refresh code the cause, who knows. I may experiment tonight, I have a few ideas to test.
Edit2:
I'm testing all kind of thing and found a bug. When the block is almost touching the bottom, if you press very fast A/B, the block will go up 1 row, then continue to go down, then go up one row, etc indefinitely.
Maybe not related to the refresh bug but I will continue to test.
Edit3:
Was able to reproduce the bug. It happens for most block (except the square) when it's near to have an impact. It's like the block is trying to re-ajust itself depending of it's environment. Because of that, you can cheat in some conditition by bringing the block back up.
I will stop to check this bug and investigate more regarding the display bug.
Edit4:
Did a lot of testing, changed some code around. Still there. Tested with emulator for now. Always happens at the top only. Cannot reproduce elsewhere. Looks like a bug similar to more than 8 sprites on the same line but it shouldn't be the case. Too tired, will do more debugging tomorrow if I can find the time.
I think I found it, not in the code but at least a proof.
Here's a memory dump of the OAM when it flickered:
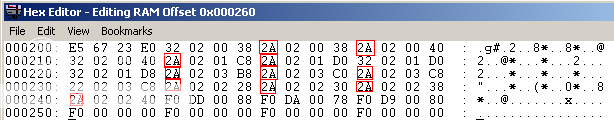
If you look properly, 12 sprites Y location is at $2A. So this mean you have a case of more than 8 sprites per scan line bug.
How to fix, good question. Maybe you will need to do some sprite cycling to reduce the effect but I'm still no expert on the nes to give any good advices yet.
Hope this information will help you find a proper solution. Now I need some sleep

Banshaku wrote:
You said that there is only 17 sprites at the same time on the screen. Ok, I can see that but what about the 47 that are not in used at the moment?
Right after drawing all the sprites, it sets the rest to y=$F0.
Quote:
Second question, wouldn't it be possible to put the next block in the background instead of a sprite? I guess one of the reason it was not done must be because of palette limitation
Correct. I'm at work on break at the moment, so I don't have access to the source code, but it goes something like this:
$3F01: grays
$3F05: unused
$3F09: player 1 frame (dark, medium, light)
$3F0D: player 2 frame (dark, medium, light)
$3F11: player 1 falling piece (dark, medium, light)
$3F15: player 2 falling piece (dark, medium, light)
$3F19: player 1 next piece (dark, medium, light)
$3F1D: player 2 next piece (dark, medium, light)
In fact, I had to leave out hold piece and multiple previews, which are required in the Tetris Guideline since 2001, purely because of palette limitations.
Quote:
and/or the problem that you can only update it when the screen is off
The game already turns the screen off 10 lines early to be able to fit a 200-tile update into NTSC vblank. If VRAM update time were the issue, I could just delay preview updates until the line clear animations ended. But palette space is the issue.
Quote:
I'm testing all kind of thing and found a bug. When the block is almost touching the bottom, if you press very fast A/B, the block will go up 1 row, then continue to go down, then go up one row, etc indefinitely.
The behavior you're seeing is called
floor kick. Have you tried doing the same thing in Tetris DX (for Game Boy Color) or Tetris DS (for Nintendo DS)?
Quote:
Was able to reproduce the bug. It happens for most block (except the square) when it's near to have an impact. It's like the block is trying to re-ajust itself depending of it's environment.
Yes. In general, such adjustments are called
wall kicks, and they have become common in recent block games.
Quote:
Because of that, you can cheat in some conditition by bringing the block back up.
This "cheating" is even worse in Guideline games such as Tetris DS. See
one of the things TDS allows and
why.
tepples wrote:
Right after drawing all the sprites, it sets the rest to y=$F0.
After posting my message I scanned the code and saw it. But in the game loop it reset the sprite every time, which seems a little bit overkill but doesn't have any impact on the display bug (I commented the code to see how it would react in an emulator).
tepples wrote:
The game already turns the screen off 10 lines early to be able to fit a 200-tile update into NTSC vblank. If VRAM update time were the issue, I could just delay preview updates until the line clear animations ended. But palette space is the issue.
After my last post regarding the more than 8 sprites on a scan line, I don't think anymore that blanking is the cause. I made on purpose the blanking go wild, removing some code and changing the order of it, making the screen flash (etc) and the bug on those blocks was still there.
What I want to try during lunch (if I do have time) is to create a check the nmi counter flag and if it's a odd value, write the sprites in ascending order and when it's not, descending. It's not a "great" sprite cycling algorithm but enough for debugging purpose. I want to see how much it will impact the display because of sprite priority.
Regarding the wall/floor kick, I didn't know
I only played tetris on the nes and the old game boy so I have no knowledge about these new rules. I tested it back on an emulator this morning and all of the nes ones doesn't have this behavior.
And I checked how did they avoid the more than 8 sprites per scan line issue because of the next block:
- Tengen tetris just put them at the top and never let the player's current block overlap
- Nintendo tetris 1 is one player so this issue never happen
- Nintendo tetris 2 cover the players block at the top with the background one's so they will never overlap
- BPS tetris is only one player so no issue again
- BPS second one does have the same issue as tetramino (next block and current block overlap) but it flicker like hell in other case so I would say there is more chance that is a poor coding issue in that case
If I can test it during lunch (sprite cycling), I will tell you my results.
The misbehavior you describe is similar to the misbehavior I see on emulators, where the PowerPak has even more flicker.
Banshaku wrote:
Regarding the wall/floor kick, I didn't know
I only played tetris on the nes and the old game boy so I have no knowledge about these new rules.
Interesting.
Quote:
- Tengen tetris just put them at the top and never let the player's current block overlap
I was going to do something like that (put previews slightly up from where they are), but at the time, I was unsure how much
safe area I could be assured of. But now that I've read up on the issue:
- In previous topics, we have determined that an NTSC-compatible 240p picture is the size of 280x240 NES dots, and PAL-compatible 288p is 280x288.
- The NES generates a 256x240 pixel picture, centered vertically but off-center to the right by a couple pixels.
- TVs draw the picture slightly bigger than the screen, hiding a margin called overscan.
- Important information must not be displayed in the overscan. TV engineers have come up with sizes for a "safe area" that won't end up in overscan on the vast majority of TVs, which can be expressed as a percent of the width and height. The BBC recommends using 90 percent; a major gaMe conSole maker recommends 85 percent.
- So the center 240x208 pixels should be visible on most NTSC TVs.
This means I could move the fields down by 8 pixels from where they are, down to where Tetяis by Tengen puts them, and they'd still be visible. How close do the fields in Tengen's game get to the edge of your TV, if that's available to you?
There's also the pirate-original "Poke Tetris" whose menus look like Tengen's and whose fields are in the same place.
The one thing that Tengen's game does that I
don't want is putting the previews in the corners. I want them directly above where the pieces will come out, like in Arika's Tetris The Grand Master, so that the player can plan how many times to press left or right for the next piece.
Quote:
- Nintendo tetris 2 cover the players block at the top with the background one's so they will never overlap
It also has a shared preview, which the other games don't have. I could do this without a shared preview, but it would push the next piece too close to the score and lines. But if I moved the fields down, I could draw the preview in OAM 1-9 and the falling pieces in OAM 10-17 marked as behind the background.
Quote:
- BPS second one does have the same issue as tetramino (next block and current block overlap) but it flicker like hell in other case so I would say there is more chance that is a poor coding issue in that case
You mean Tetris 2 + Bombliss? That game's 2-player mode has no score/lines indicators, both sides have the same frame color, and the preview is actually half size.
tepples wrote:
The misbehavior you describe is similar to the misbehavior I see on emulators, where the PowerPak has even more flicker.
As for my latest testing, I could only do it in an emulator since my eprom writer is a slug (~4/5 min for 512k...). So the forced vblank bugs and code swapping to see if the flicker was still there was done only in an emulated environment.
Quote:
How close do the fields in Tengen's game get to the edge of your TV, if that's available to you?
The tengen version is not available in japan to my knowledge (I could be wrong). I did my research this morning in the train with an emulator on the DS. From the emulator view, it was not at the top of the screen completly. There was a border in between.
Image taken from emulator:
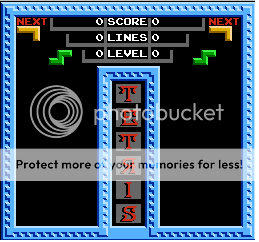
The next block will never overlap the current block in this situation.
Quote:
The one thing that Tengen's game does that I don't want is putting the previews in the corners. I want them directly above where the pieces will come out, like in Arika's Tetris The Grand Master, so that the player can plan how many times to press left or right for the next piece.
Oh. Didn't read that comment properly. Unless you move the score and line to another location and put there more minimalist (and explain it in the demo screen) so you can put the block higher, hmmm... Not much to do then.
I wanted to do some sprite cycling test but didn't have enough time and wasn't sure if it was done at many place since I don't know the code base well yet. My guess is that I must replace the sprite DMA code only in the main game_loop after the vblank code and see what happens.
The only quick test I did is to add the famitracker sound driver to add an extra stress during the game so I can see if the timed vblank code could be the cause. But... It started, the music was there but crash & burned during the game

Oh well for the quick test without knowing the code then...
Edit:
Quick question that just came after reading the code. In your nmi handler, you have a variable called vblanked. Everytime a NMI
is launched during vblank (this is where I need to be corrected if I'm wrong), the vblanked variable is increased.
This variable is used in the game_loop to check the status of the vblank so you can do some video processing. If my understanding of the NMI is right, why do you need to wait that the variable roll back to 0 to check the status of the vblank? Is it possible that you're could be waiting too much and that could cause the bug? Wouldn't you just need to check if the vblanked variable changed since the content of the previous loop and you may need a "previous_vblanked" variable?
Or my understanding of NMI and your code is wrong?
Edit2:
Removed for fun the wait vblank code. Funky line at the bottom but flickers still there. So waiting too many nmi case is removed.
Changed the code from sprite DMA to normal write. Break the game display timing, sprite are shown and flickers are still there.
My last test was to write the sprite data at $0300, from 0 to 255 on even one (from my counter) and on odd ones I reversed the order. Display timing was broken (expected), priority of tile changed (back became front) but some flicker on the side are still seen.
I will have to think about something else for now.
I did more tests but without success. I guess I reached my limit regarding my current nes knowledge.
For now I know more about your code base than the nes so I cannot move forward with appropriate tests. It ether a more than 8 sprites bug or something related to blanking since a lot of processing is done there. You game seems to requires very precise timing and if you don't, the screen gets affected. If feels like a VSYNC bug on dos where the sync is not done properly and some part of the screen flickers. Don't know if DMA transfer could have any impact if done in specific conditions since it's related to sprite so. hmmm... But since I don't know enough, I cannot find a way to test it.
Sorry to have not been more useful than that. I hope you find it soon. If you do, I really want to know what you fixed.
Banshaku wrote:
You game seems to requires very precise timing
Is this Battletoads?Quote:
and if you don't, the screen gets affected. If feels like a VSYNC bug on dos where the sync is not done properly and some part of the screen flickers.
Well at least it flickers and doesn't crash due to the vblank_instead system. A lot of emu authors wish they could say the same for some Rare games.
Anyway, I have some ideas how I could redo the top of the playfield frame to fit under the 8 sprite limit. As for the flicker in the preview on the PowerPak, it seems to go away when a piece lands (but before it locks).
Is your program waiting the proper amount of time to allow the PPU to stablize on bootup, before writing to any PPU registers? This is the absolute only thing I can think of that would cause weird glitches on the hardware, where it wouldn't on emulators.
Then again, if this is the powerpak, it probably wouldn't matter... but it's all I've got. *shrugs*
Drag wrote:
Is your program waiting the proper amount of time to allow the PPU to stablize on bootup, before writing to any PPU registers?
Yes, and I assume the PowerPak BIOS is doing the same.
I've uploaded version 0.32, which changes how the falling piece is drawn to virtually eliminate the sprite dropout that caused problems even in emulation. Any remaining flicker is almost certainly a result of a poorly understood quirk of the NES or the PowerPak. Can I get some more testing done?
tepples wrote:
I've uploaded version 0.32, which changes how the falling piece is drawn to virtually eliminate the sprite dropout that caused problems even in emulation. Any remaining flicker is almost certainly a result of a poorly understood quirk of the NES or the PowerPak. Can I get some more testing done?
If I can find some time (since I have to re-edit it for MMC3), I will test it on my dev cart. I will see what I can do this week.
tepples, I looked into this and (6 hours later) you were right about a new hardware quirk. Disabling rendering before the end of the frame indeed causes erratic behavior of sprite RAM on the next frame, regardless of whether you use DMA or manually copy bytes to it. It's not all bad, as I found a way to avoid it: disable rendering during pixels 66 to 254 (approximate), and ensure that any intersection with sprites is on their last row. If that scanline intersects a sprite's earlier rows, you get the erratic behavior no matter when you disable rendering. This means if you're using sprite hit for timing, you'll have to either settle for a visual glitch near the end of that scanline, or have the next scanline black and wait until its middle of before disabling rendering. There's no reasonable way to get the glitch right at the end of the scanline, because the timing variance when synchronizing to sprite hit is too great (around 21 pixels at best).
I think the following fixes things (I got the game running on my RAM devcart). Put sprite 0 at X=248, Y=223, and make it use tile $B1. Set tile $B1 to be a horizontal bar at the bottom (0,0,0,0,0,0,0,$FF). This way it collides on its last row. Also, insert a ~55-clock delay loop just before "BEGIN VRAM UPDATE" (you might be able to reduce the delay slightly).
I'll try to post my hardware test code soon.
blargg wrote:
tepples, I looked into this and (6 hours later) you were right about a new hardware quirk. Disabling rendering before the end of the frame indeed causes erratic behavior of sprite RAM on the next frame, regardless of whether you use DMA or manually copy bytes to it. It's not all bad, as I found a way to avoid it: disable rendering during pixels 66 to 254 (approximate), and ensure that any intersection with sprites is on their last row. If that scanline intersects a sprite's earlier rows, you get the erratic behavior no matter when you disable rendering. This means if you're using sprite hit for timing, you'll have to either settle for a visual glitch near the end of that scanline, or have the next scanline black and wait until its middle of before disabling rendering. There's no reasonable way to get the glitch right at the end of the scanline, because the timing variance when synchronizing to sprite hit is too great (around 21 pixels at best).
Sorry, it's kind of hard to follow what you're saying, so I may sound ridiculous. Are you saying that if you disable rendering, you have to disable it on a scanline that doesn't intersect a sprite unless it's the sprite's last row of pixels? Also, what kind of "erratic" behavior does this cause? Is it just flickering or complete unpredictability?
How do all the commercial games that disable rendering earlier work fine then?
Celius wrote:
Are you saying that if you disable rendering, you have to disable it on a scanline that doesn't intersect a sprite unless it's the sprite's last row of pixels? Also, what kind of "erratic" behavior does this cause? Is it just flickering or complete unpredictability?
Correct. The erratic behavior in my tests is a pair of sprites disappearing on the next frame. Which pair disappears can depend on which exact PPU clock rendering is disabled on. Since most games don't synchronize to exact PPU clocks, this means that a different pair of sprites will be affected each time, causing flickering (exactly what we see in Tetramino).
tokumaru wrote:
How do all the commercial games that disable rendering earlier work fine then?
I don't know. Perhaps they avoid the conditions that cause the glitch, avoid using the particular sprites affected, or maybe they
don't work fine, since the effect so far just seems to be some extra flicker on a few sprites.
Here's the ROM and ca65 source that demonstrate the issue. I imagine an examination of the PPU rendering steps during a scanline might shed light on the pattern of sprites affected.
sprite_bug.zip
I tried to hold back as much as I could on suggesting a new PPU quirk because only a bad workman rushes to blame his tools. It gave me a chance to improve the overall quality of control processing and sprite handling, to the point where I might even be able to add the ghost piece seen in newer Tetris products. Thank you, blargg, for figuring out what was really going on, helping me make the sprites 100% flicker-free on my PowerPak, and confirming that I am not a bad workman. You've got a credit in the change log of the forthcoming version 0.33.
tokumaru wrote:
How do all the commercial games that disable rendering earlier work fine then?
I don't know. Perhaps I'm triggering a bug like the one that Andrew Davie's team triggered in early builds of The Three Stooges (OAM retention time decreases when some PPU revisions overheat). It just goes to show that there's a lot we still don't know about the PPU.
blargg wrote:
I think the following fixes things (I got the game running on my RAM devcart). Put sprite 0 at X=248, Y=223, and make it use tile $B1. Set tile $B1 to be a horizontal bar at the bottom (0,0,0,0,0,0,0,$FF). This way it collides on its last row.
I already had a tile like that: tile $5F (ASCII for the underscore). I have been reserving $B0-$CF for a subtitle, like on the DreamEmulation CD.
Well if it's only flickering, that's not the worst thing in the world. Actually, I kind of like the way sprite flickering looks; it characterizes NES games. I believe it was kyuusaku who was saying the same thing about attribute glitches, and I can see where he's coming from with that. If it doesn't cause RAM corruption where random values are just littered all over the sprite page, I guess it's alright. I was really worried because in my polygon sequence engine, I use a sprite zero hit to shut the screen off 40 scanlines early, spilling 40 scanlines out of Vblank, and I have sprites on screen with this engine. So this seems like a perfect candidate for the corruption.
There's probably tons we still don't know about the PPU. I can't imagine trying to find this bug though; I wouldn't have the slightest clue where to begin. Yes, thanks blargg for going through tedious crap to find yet another weird quirk with the NES
.
The Garage Cart #1 intro turns the screen off mid-frame and does a 2nd sprite DMA. I do seem to remember a little bit of flickering on the 2nd part that apparently went away after I had adjusted the delay timing to fix something else. (The first part was mostly a dim starfield, so flickering could've been unnoticed or nicer).
I usually have been using a horizontal line for sprite #0, otherwise maybe I would've been stuck with that bug and never known why until now. I do know it's been said to do that, but I don't know where.
That's some quality obscure info. The PPU needs an errata sheet.
OK, I've done some OAM memory examination and am making more sense of what happens. It looks like disabling rendering mid-scanline confuses the OAM refresh circuitry (at least I'm assuming it does refresh, being DRAM and all), so that when it runs at the beginning of the next frame, the first refresh writes to wherever it was when rendering was disabled. So if it was at sprite 20 before, it will copy the first two sprites over sprites 20 and 21 (apparently refresh is done in blocks of 8 bytes). I think I ran into this bug a while back, but never tracked it down. Hopefully I'll come across that code again and be able to verify it being the same thing. I've encountered similar bugs in the Game Boy hardware (DMG), where OAM and sound wave RAM can become corrupt in the same manner, with other parts duplicated.
Here's an example. Dashes every 4 bytes, for clarity. The first two sprites have different tile and attribute, to distinguish them, and the rest use tile and attribute 03.
Code:
80 04 00 80-1A 05 01 8B-1A 03 03 96...80 04 00 80-1A 05 01 8B-46 03 03 80-46 03 03 8B-46 03 03 96-46 03 03 A1...
^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^
80 04 00 80-1A 05 01 8B-1A 03 03 96...3B 03 03 96-3B 03 03 A1-80 04 00 80-1A 05 01 8B-46 03 03 96-46 03 03 A1...
^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^
80 04 00 80-1A 05 01 8B-1A 03 03 96...3B 03 03 96-3B 03 03 A1-46 03 03 80-46 03 03 8B-80 04 00 80-1A 05 01 8B...
^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^
Each line is with the PPU disabled one PPU clock later than the previous. You can see how the first 8 bytes get duplicated in different locations based on that. This is what happens to sprite data written at the beginning of the frame
after the one where PPU rendering was disabled early. I read it back after that frame was displayed. I get the corruption even if I just let that frame run for a few scanlines, the disable rendering and read it back immediately.
If it leaves off on sprite 63, would it overwrite sprite #63 and sprite #0 with sprite #0 and #1? Again, sorry if that sounds ridiculous. I am still a little rough when it comes to the really technical things inside the PPU.
tepples wrote:
I tried to hold back as much as I could on suggesting a new PPU quirk because only a bad workman rushes to blame his tools.
But you should never hesitate to blame it when you can't find anything else being wrong ;)
I've blamed visual studio for a few problems in the past and found out that it actually was visual studios fault :)
One time it was a bad memory leak and after lots of debugging I discovered that it was a problem in the stream classes in STL shipped with the first version of VS.NET 2005.
Celius wrote:
If it leaves off on sprite 63, would it overwrite sprite #63 and sprite #0 with sprite #0 and #1?
It seems to affect pairs only, with the first of the two an even-indexed sprite. So it could modify 62 and 63, but not 63 and 0. Try running the ROM to see it in action.
So actually, sprite #0 and #1 could never get corrupted, since they would be overwritten with #0 and #1. This is a huge relief, because I just have a project where everything depends on a sprite #0 hit.
Also, I don't have the means to test this on hardware (I'm more of a software guy, but I plan to expand my hardware knowledge/tools). I don't think this would work really testing it on an emulator, because this is a newly discovered quirk.
In my engine, I don't do sprite DMA every frame (it's more like every 5-7 frames). So are those sprites permanently overwritten until I do another DMA transfer?
Another question I have is what if it's like in my case where bars are blanked on top and on bottom of the screen, and it encounters hidden sprites in the top bar? What effect will that have if there are hidden sprites in the top bar, and visible/rendered sprites in the on-screen portion?
Sorry for all the questions, it's just something I should be concerned with. I guess if that's a problem, for this particular project I could place all unused sprites in a different area.
Celius wrote:
So actually, sprite #0 and #1 could never get corrupted, since they would be overwritten with #0 and #1.
Assuming the cause is what I described.
Quote:
In my engine, I don't do sprite DMA every frame (it's more like every 5-7 frames). So are those sprites permanently overwritten until I do another DMA transfer?
Seems so. And if you trigger it on each of these 5-7 frames, you'll have different sprites getting corrupt, so more than just two will disappear.
Even ignoring this hardware glitch, I don't know if it's a good idea to depend on OAM keeping its contents over several frames without being rewritten.
Quote:
[...] what if it's like in my case where bars are blanked on top and on bottom of the screen, and it encounters hidden sprites in the top bar?
Hmmm, I wonder if delaying of
enabling of rendering (ala Battletoads) prevents the glitch. Or by bars at the top do you mean that the PPU is enabled at the start of the frame, then you disable it near the top for a few lines, then re-enable it?
Quote:
What effect will that have if there are hidden sprites in the top bar, and visible/rendered sprites in the on-screen portion?
Within the "safe" region of the scanline, the glitch seemed to occur anytime there was any sprite falling on that line.
Quote:
[...] if that's a problem, for this particular project I could place all unused sprites in a different area.
Elaborate. I don't see what problem this is addressing.
Is this possibly why a bunch of commercial games write $00 to $2003 before using the sprite DMA?
Or does that not prevent the glitch?
Edit: Nevermind, it seems that I've gotten the meanings of "DMA" and "refresh" confused. :S
Yeah, my polygon movie engine runs at like 12 software FPS, and every software frame, I do a DMA transfer (So 60/12 = every 5 frames). So I'll come up with a solution so all my sprites won't get corrupt.
So here's how my polygon engine uses blanking in a very tiny nutshell: uses sprite #0 hit at around scanline 200 and shuts off the screen until it wraps around to scanline 40 on top in the next frame(so 80 scanlines and vblank). Scanlines 40-199 are displayed (rendering is enabled). All of my unused sprites were placed at Y = $FF, so the glitch would occur since rendering is disabled in that location.
But what I'm wondering about is if the glitch would occur if all of my unused sprites were placed in the top blanked bar, in which case all of the used sprites would be rendered after that. If the glitch wouldn't occur for some reason, then I'd just solve the problem by placing unused sprites in the top bar.
Sorry, my last sentence of the last post didn't make much sense. What I was trying to say is that if the glitch will occur by me placing unused sprites in a blanked area, I can probably put them somewhere else. I could shave off 8 pixels of the rendered area and put all the unused sprites in that 8-pixel-tall row. And by shave off, I mean just don't put anything useful there. It will still be rendered, but it will serve as a hiding place for my unused sprites without causing the glitch. And I could still do a DMA transfer every 5 frames wtihout bad glitches.
About sprite #0 hit. If I'm using a sprite #0 hit for blanking purposes, the glitch will happen, as the PPU will be shut off and sprite #0's pixels will cross the "danger" area in the next scanline. But I suppose I could place sprite #0 so that it's last row of pixels is all that is hitting the solid tile below it. This way, sprite #0 hit would occur, but the blanked region would not encompass any of sprite #0's rows (since by the time I shut off the PPU, it has already drawn the last row of sprite #0, which is the only thing that could cause the sprite #0 hit).
I hope what you're saying is really true, because it would be nice just to leave sprite #0 where it is so even if the glitch occurs, sprite #0 will be overwritten with sprite #0, which obviously is no problem.
It's good to see that all the testing resulted in finding a new quirk regarding the PPU. It's great that Blarg found it. My technical level about the nes was too low to be able to find something like this.
In a way it's exciting to see that there's still some hidden things that we don't know.
Celius wrote:
[... the program waits for] sprite #0 hit at around scanline 200 and shuts off the screen until it wraps around to scanline 40 on top in the next frame(so 80 scanlines and vblank). Scanlines 40-199 are displayed (rendering is enabled). All of my unused sprites were placed at Y = $FF, so the glitch would occur since rendering is disabled in that location.
How would the unused sprites be a problem if they are at Y=$FF? You're disabling rendering well before that, so they don't fall on that scanline. So if you're disabling on scanline 200, then only sprites with Y positions from 194 to 200 (assuming double-height is off) would cause the glitch.
Quote:
If I'm using a sprite #0 hit for blanking purposes, the glitch will happen, as the PPU will be shut off and sprite #0's pixels will cross the "danger" area in the next scanline. But I suppose I could place sprite #0 so that it's last row of pixels is all that is hitting the solid tile below it. This way, sprite #0 hit would occur, but the blanked region would not encompass any of sprite #0's rows (since by the time I shut off the PPU, it has already drawn the last row of sprite #0, which is the only thing that could cause the sprite #0 hit).
Yes, this is the idea I mentioned before. Just remember that you must disable rendering before the end of the visible scanline. The point where you disable rendering will vary each frame since you can't synchronize exactly to when sprite #0 hits, so if that scanline isn't all black, the right edge will wiggle around (implement it and you'll see what I mean).
Quote:
I hope what you're saying is really true, because it would be nice just to leave sprite #0 where it is so even if the glitch occurs, sprite #0 will be overwritten with sprite #0, which obviously is no problem.
Which sprites are overwritten is based on the exact PPU clock you disable rendering on, which makes it basically unpredictable. Maybe we can find some circumstances where the glitch reliably affects only one pair of sprites. Actually, I have seen a possibility of this, but it needs more study. For the time being, to avoid the glitch you must disable rendering around pixels 60-250 of the visible scanline, and have no sprites or only the last rows of sprites visible on that line.
EDIT: corrected sprite Y positions that cause glitch (not 193-200 as example previously claimed).
Ah, I see. I was thinking that the glitch occured if any sprite was in the entire blanked area. So if you shut off the PPU at scanline 200, and there are no sprites touching that scanline, no glitches will happen?
About the scanline wiggling like SMB3's status bar; mine doesn't do that. I have a black solid sprite colliding with a black solid tile, and color #0 is black with no PPU data below it. So no wiggling will happen. I made it this way because there's a time where I have to execute code that takes a variable amount of time. When executing this, I don't do any blanking until I'm done and wait till the it reaches a sprite #0 hit. Though if it's beyond scanline 200, I'll wait till the next frame. Since I do this, I had to make a completely invisible switch from blanking to not blanking.
Let me see if I have this right. If you blank on scanline $FF, you must have all unused sprites at $F0-$F8 (If it's on scanline $F8, only the bottom row of the sprite's pixels will contact $FF, which you said is alright). But if you blank anywhere before scanline $FF, you'll be safe hiding your sprites at Y = $FF?
Crap, I'm dropping the ball totally. Let's try a different approach, since I'm failing at the current one. Consider numbered scanlines and possible sprite Y positions A-E (each 8 pixels tall):
Code:
...
192 A
193 AB
194 ABC
195 ABC
196 ABC
197 ABC
198 ABC
199 ABC
200 BC PPU rendering is disabled on some pixel between 66 and 254
201 CD
202 DE
203 DE
204 DE
205 DE
206 DE
207 DE
208 DE
209 E
...
A sprite in position A, B, or E won't cause the glitch. A sprite in position C or D (and the others between these two) will.
EDIT: maybe correct this time, but who knows (ugh).
EDIT 2: further testing shows that there are 8 Y positions that cause the glitch, not 7 as shown before (even if sprite's first row is on
next scanline, it causes glitch). Diagram above is fixed.
Okay, thanks for clearing that up. That's a really weird quirk. I know if I tested code out on hardware and had that error, I'd never have figured that out (I would need at least 5 more years of experience in electronics to begin forming a thought about some day having the means to do that).
So I guess after my sprite #0 hit, I'll just have to put like 20 cycles worth of wasting time to guarantee that I'm in the safe area (66-254). That should do the trick, since the sprite #0 hit waiting loop doesn't have much of an unpredictability window in terms of timing (it's only 7 cycles, so it's possible to waste a certain amount of time to guarantee that you'll fall into the 66-254 window by the time you want to disable rendering).
Please see my rewritten, corrected previous post first. Much better than before.
As for adjusting the rendering disable time, can you just adjust sprite #0's X position? Then you don't need any delay loop. An empirical way to fine-tune the X position is to temporarily make that last scanline non-black, allowing you to see where rendering is being turned off (as well as how much it's varying), then adjust the X position until it's comfortably between 66 and 254.
blargg wrote:
An empirical way to fine-tune the X position is to temporarily make that last scanline non-black, allowing you to see where rendering is being turned off (as well as how much it's varying), then adjust the X position until it's comfortably between 66 and 254.
When I was fixing Tetramino, I made sure that the write to PPUMASK fell close to X=128 by turning on the monochrome bit.
Oh, I'm pretty sure I understand. Your new post makes much more sense, yes.
So the safest way to go would be to have the absence of sprite rows (excluding the last one) crossing the scanline on which rendering is disabled, right?
Also, if I'm understanding correctly, it seems no matter where you start early vblank, it's possible to hide your sprites somewhere.
I seem to recall that if $2003 is non-zero it causes sprites 0 and 1 to change to whatever sprite pair $2003 is pointint to. For instance, if $2003 was $7D (part of sprite 31), then sprites 30 and 31 would replace sprites 0 and 1. I might not be remembering right though (it was quite a while ago when it came up). I wonder if this glitch is related to that one.
I'm also confused about exactly what is causing the glitch. If shutting off the PPU mid-frame causes sprites to be overwritten where the OAM engine was looking at the time of the shut-off, then why is it that the problem only occurs if sprites are in-range for the following scanline? It isn't like the OAM engine does nothing if no sprites are in-range - it actually has to cycle through OAM to check for in-range sprites. Does the problem only happen after a sprite is found to be in-range on a scanline? If so, then why are cycles 0 through 63 (the "init" phase) off limits for shutting off the PPU? The OAM engine doesn't even look at any sprite data during this period (reading $2004 returns $FF).
Out of curiosity, what value is returned if you read $2004 after diabling the PPU, but before writing anything to $2003 or $4014?
Celius wrote:
So the safest way to go would be to have the absence of sprite rows (excluding the last one) crossing the scanline on which rendering is disabled, right?
Yes. Note I updated the diagram
again (Y positions from scanline-6 to scanline+1 cause the glitch).
Celius wrote:
Also, if I'm understanding correctly, it seems no matter where you start early vblank, it's possible to hide your sprites somewhere.
Sure, anywhere but the 8 Y positions that cause the glitch.
dvdmth wrote:
I seem to recall that if $2003 is non-zero it causes sprites 0 and 1 to change to whatever sprite pair $2003 is pointint to. For instance, if $2003 was $7D (part of sprite 31), then sprites 30 and 31 would replace sprites 0 and 1. I might not be remembering right though (it was quite a while ago when it came up). I wonder if this glitch is related to that one.
Aha! I just tested and you're right. The source 8-byte group is whichever one SPRADDR ($2003) is within, and the destination is wherever refresh or whatever left off. Normally the destination is the first 8-byte group, but the glitch causes that to be another group.
So if you could predict
which group the glitch leaves the write pointer at, you could set SPRADDR to that at the beginning of the frame. I've found that when only sprite #0 intersects the scanline rendering is disabled on (in a way that causes the glitch), during pixels 66-254, it always leaves the write point at the 5th 8-byte group. So setting SPRADDR to $20 at the beginning of the frame should neutralize the glitch (and indeed it works in my test ROM).
But doing further testing of different sprites intersecting the scanline rendering is disabled on, it seems only the first 6 sprites cause the glitch (and always the same pair). If later sprites intersect, it doesn't occur (as long as rendering is disabled on pixels 66-254). Very strange.
Quote:
Out of curiosity, what value is returned if you read $2004 after diabling the PPU, but before writing anything to $2003 or $4014?
$80, but I'm not sure how that helps.
After disabling PPU before end of frame in a way that causes glitch next frame, SPRADDR is always zero. I determined it by writing to SPRDATA $00 followed by 255 $FF bytes, then finding which byte of OAM was zero. I also verified that only one byte was zero during the scan.
I also did a quick test of delayed PPU enabling and I'm not seeing any OAM corruption. It might be that enabling PPU rendering at a particular clock in will trigger it (the same clock the frame normally would start at), and I'm not enabling on that clock in my test. Or maybe it only occurs when the PPU is already enabled at the start of the frame.
Some clarification:
1. If sprite 0 is the only sprite in range, then OAM $20-27 is corrupted. Suppose sprite 1 is the only one in range. Which sprite pair is corrupted? If I'm reading right, you're saying that the same pair is corrupted (OAM $20-27). Or, are you saying sprite 1 causes the same pair to be corrupted, but it's a different pair from sprite 0 (e.g. $40-47 instead)?
2. Suppose both sprites 0 and 1 are in range. What sprite pair gets corrupted in this case? I want to know if the corrupted sprites (1) depends on the total number of sprites found, (2) depends on the first (or last) sprite found, or (3) is always $20-27 (provided shut-off is in the OAM scanning period mid-scanline).
3. If none of the first six sprites are in range, there is no corruption? Are you sure of this? Perhaps you were shutting off the PPU before the seventh sprite was evaluated? (I have an idea what might be causing the bug, but my idea will go out the window if only sprites 0-5 cause the problem.)
4. What happens if $2004 is read during the first 64 cycles of the pre-render scanline?
Tetramino 0.33: no more flicker, among numerous other changes.
I was hoping to get answers to my questions, but oh well. Here's my idea of what's happening.
My theory is that the corruption is being caused by the fact that there are two different sections of OAM. The primary OAM, which is 256 bytes, contains all 64 sprites and is ultimately what is written to during sprite DMA, etc. Secomdary OAM is 32 bytes and contains the 8 sprites that are in range for a particular scanline. At the start of a scanline (cycles 0-63), the sprite engine sets all bytes in secondary OAM to $FF (reading $2004 returns $FF during this period). During cycles 64-255, primary OAM is scanned and any sprites that are in range are copied to secondary OAM. During H-Blank (cycles 256-319), secondary OAM is scanned, and each in-range sprite is processed for display on the next scanline (CHR data is fetched, etc.). The sprite engine is inactive from cycles 320-340.
At the end of each scanline, the secondary OAM address will always be zero, but during a scanline (including H-Blank) this address becomes non-zero. What I'm thinking is that if the secondary OAM address is non-zero at the time the PPU is turned off, then its address will determine which pair of sprites will be corupted at the start of the next frame. There are 32 bytes in secondary OAM, and there are also 32 sprite pairs in primary OAM, so my guess is that if you multiply the secondary OAM address by eight, you'll get the first byte in primary OAM that gets overwritten.
If this is the case, then turning off the PPU between cycles 64 and 255 on a line with no in-range sprites will not cause the glitch, since the secondary OAM address will stay at zero. If there are in-range sprites, then the address will become non-zero and cause the glitch to happen. During H-Blank, and during the first 64 cycles of each scanline, the secondary OAM address always changes whether there were sprites on that line or not. Theoretically, the address should be zero between cycles 320 and 340, but that's probably too small of a window to be used in most applications.
I would like to see this tested. I hope there's a way to predict the corruption so that emulators can implement it. Nestopia does have the recent controller read/DPCM bug implemented - maybe this is another one that could be added to that emu.
I understand this topic is pretty old, but I think I was having an issue related to this. The issue would -only- happen on hardware, as a result of a failed sprite #0 hit.
In my current project, I have a status bar at the top, with a sprite #0 hit happening at pixel 31, 204. After this, the scroll is appropriately set and whatnot. In my test level, I have a part where the player can enter a cave by pressing the up button. When that happens, the "level initialize" routine is called to load the next part of the level. Since there is so much updating, I actually have to disable rendering and the NMI. This disabling of rendering was originally happening mid-frame. After that, a ton of updates would occur, and I would clear out everything but sprite #0 in my RAM page dedicated to OAM. At the end of the routine, I would wait for the next Vblank, re-enable rendering and perform a DMA transfer as well as re-enabling the NMI. The code I performed was as follows:
Code:
lda #$00
sta $2000
sta $2001
sta Standard.$2001
sta Standard.$2000
....
;Whole ton of PPU updates
....
lda $2002
-
lda $2002
bpl -
lda #$1E
sta Standard.$2001
sta $2001
lda #>Game.ObjectDraw.OAMPage
sta $4014
bit $2002
lda #$88
sta Standard.$2000
sta $2000
rts
Interestingly enough after this routine, what sometimes happened, and what sometimes didn't, was that the screen would come up displaying my status bar, and the background below, but absolutely no game logic was being processed. I added in some native debugging features to view the contents of RAM while testing the game on the powerpak, and I noticed the stack was overflowing as a result of the game never exiting the NMI. From a little more testing, I narrowed it down to sprite #0; it was never detecting the hit.
What was strange is I was able to see the tile used for sprite #0 hits where it was supposed to be on the screen. Also, the page I used for DMA transfers appeared normal. The only thing was, since the game logic loop wasn't able to finish up its usual game logic in time for the first execution of the NMI, PPU updates were still locked, so it wasn't performing a DMA transfer within the NMI handler (It only performed the one at the end of the level init routine).
After hours of pulling my hair out, I noticed something that I think may be the cause of this problem. When I was disabling rendering, it was midframe, and the glitch would only happen when the player's sprite was on the scanline being rendered at the time of disabling! As I've said before, no emulator was able to recreate this behavior; it only happened on hardware. Looking at the contents of RAM, I saw absolutely nothing indicating there should not have been a sprite #0 hit when rendering was re-enabled.
So, with that aside, what I'm wondering is how I can effectively avoid this. The first thing I did once I discovered this was wait for the NMI to disable rendering. So I replaced:
Code:
lda #$00
sta $2000
sta $2001
sta Standard.$2001
sta Standard.$2000
with
Code:
lda #$00
sta Standard.$2001 ;Clear virtual PPU register
lda Standard.VBLCount ;Wait for NMI; it will shut off the screen
-
cmp Standard.VBLCount
beq -
sta $2000
sta Standard.$2000
So that the NMI handler would see that I wrote #$00 to the virtual $2001 register, and then in turn write $00 to the real $2001 register (and of course, skipping the wait for sprite #0). After that NMI is executed (which would be seen by the difference of the originally loaded VBLCount and the updated VBLCount variable), the NMI would be shut off. So all together, this code would be disabling rendering during actual Vblank, and then shutting off the NMI. Would this be an adequate solution to the bug discussed in this thread?
Sorry if this is not enough information, or too much to make sense of. If clarification is needed, I would be happy to provide =).
Celius wrote:
Would this be an adequate solution to the bug discussed in this thread?
I think so. The whole problem is that disabling sprites while the sprite rendering logic is running causes it to act funny when they're enabled back. Since no sprites are rendered during VBlank, that seems to be a safe time to disable rendering.
Some games disable sprites for 1 scanline, then turn off the screen at the next scanline. Is this always a safe way of doing things?
As I understand it, disabling sprites and leaving the background turned on only hides the sprites. It doesn't disable the sprite rendering pipeline.
Yeah, and as I understand, the other way arround is true too : "disabling" background but not sprites only hides the BG, but the rendering pipeline still works as usual.
At least I was able to toggle the BG on/off without having any problems with scrolling (with sprites on) which soft of "proofs" this.
I guess the PPU only enters in it's "iddle" mode when both BG and sprites are hidden.
A total proof of it would be to use MMC3's scanline counter with BG or sprites (but not both) disabled and show that it works as supposed. Does any games/demoes do this ?
Ha, I actually used this code as I wrote above:
Code:
lda #$00
sta Standard.$2001 ;Clear virtual PPU register
lda Standard.VBLCount ;Wait for NMI; it will shut off the screen
-
cmp Standard.VBLCount
beq -
sta $2000
sta Standard.$2000
And noticed that very strange things were going on visually. Sometimes, my status bar would be drawn as if PPU increment 32 was on, and there would also be very strange color glitches when the second half of the level was loaded. Hmmm.... Well, it could have something to do with:
Code:
lda Standard.VBLCount ;Wait for NMI; it will shut off the screen
-
cmp Standard.VBLCount
beq -
sta $2000
sta Standard.$2000
Because if you look, the VBL count is actually getting stored in $2000! Woops. Adding an lda #$00 before that fixed that problem right away =).
And actually, relating to what you guys are talking about, I was curious about something. Is it not safe to do BG updates while BG rendering is disabled, but sprites are enabled?
Celius wrote:
Is it not safe to do BG updates while BG rendering is disabled, but sprites are enabled?
No, it isn't. The PPU is only free for updates if both are disabled.
Bregalad wrote:
A total proof of it would be to use MMC3's scanline counter with BG or sprites (but not both) disabled and show that it works as supposed. Does any games/demoes do this ?
Chu Chu Rocket does it, when it shows a dialog box, it disables sprites, but allows background, and the IRQ to end the box happens just like it should.
Dwedit wrote:
Chu Chu Rocket does it, when it shows a dialog box, it disables sprites, but allows background, and the IRQ to end the box happens just like it should.
Have you tested with an actual MMC3 chip? Because we all know that the PowerPak can't be trusted for these things.
Did any emulator ever implement this corruption behaviour?
I'm having a hard time following this thread, because there seems to be conflicting information.
Just so I have it straight, disabling sprite rendering on a scanline that has sprites on it will cause the sprite flicker glitch, unless you disable sprite rendering sometime between pixels 64-255 within the scanline?
Or do you have to avoid disabling between pixels 64-255?
You have to avoid disabling while a sprite is in range, and you have to disable between x=64 and x=255. At least these rules worked for clearing up the flicker in LJ65 (formerly Tetramino).
So there is absolutely, positively no way to disable sprite rendering on a scanline that has sprites on it? I'm just looking at Bio Force Ape, and noticing that it disables screen rendering early. Does this exhibit the sprite glitch on real hardware?
At what (X, Y) does it disable rendering?
X position, I don't know. I was scrolling the screen with a half cut-off sprite where the rendering was disabled, and the sprite seems to be able to display itself on all parts of the scanline, so it might be disabled in hblank.
Y position, I'm not good at counting blank scanlines, but it's definitely 16 or more scanlines before the natural end of the frame. Looks like maybe 24.
You can set up a breakpoint for the PPU control registers in Nintendulator to see when it disables the rendering. Nintendulator has this nice PPU scanline and pixel counter when single-stepping.
qbradq wrote:
You can set up a breakpoint for the PPU control registers in Nintendulator to see when it disables the rendering. Nintendulator has this nice PPU scanline and pixel counter when single-stepping.
Good idea!
If I'm reading this correctly:
SLNum: 209
CPU Ticks: ranges from 306-317 / 102-105
So scanline 209, but I dunno what pixel that translates to. It's outside of the 64-255 range though.
(The breakpoint I set was on $E2BF, and I used fceux to find that address by looking for writes to $2001)
When things are in a 3:1 ratio like 306/102, it probably means the first is PPU cycles (i.e. dots) and the second is CPU cycles.
tepples wrote:
When things are in a 3:1 ratio like 306/102, it probably means the first is PPU cycles (i.e. dots) and the second is CPU cycles.
I'm aware of that, but I don't know which of the theoretical 341 pixels are the 256 that show the game screen.
So, after reading Brad Taylor's doc (which REALLY could use some visuals... this might be good for wikification), it seems that the screen rendering is turned off offscreen, during the time where the tile data for the next scanline's sprites is fetched. I'm assuming this is considered hblank, but I'm not sure.
Again, is this game susceptible to the sprite oam glitch by doing this?
Did anyone ever get around to testing this quirk for the situation where rendering is disabled for N number of scanlines, and then re-enabled, instead of just happening at the end of the frame?
I'm trying to have a black bar at the top instead of the bottom, and since I don't want the alternative dot crawl pattern of Battletoads, I have rendering enabled for 1 line just to prevent that. I wait for the previously set sprite#0 hit flag to clear to find end of vblank, delay N lines (normally one but about 20 in my current debug setting just to see what's going on) and then disable rendering in the "safe" area of 64-250.
But it doesn't seem to help, even when no sprites are intersecting. Or more specifically, it works fine for most reset states, but I can sometimes get it into a reset state where sprites get corrupted. And that seems to include sprite#0, which causes the "wait for end of vblank" sequence to fail miserably since sprite#0 doesn't get hit.
Based on the previous theories, is it even possible to do this? If the sprite evalution state machine will have been interrupted in a state of acessing secondary OAM, I guess secondary OAM should have the state from where it was turned off while scanning of primary OAM would depend on pixel location where screen was re-enabled again?
I'm also quite surprised why I never encountered this bug when making Years Behind, where I did the following seemingly more complicated sequences:
* Waiting for sprite#0 hit flag to get cleared to find end of vblank
* Enabling rendering
* Waiting for sprite#0 hit flag to get set
* Turning off rendering to re-write the palette for the status bar
* Turning on rendering
* Turning off rendering to restore the palette
* Turning on Rendering
* Finally, turning off rendering prematurely before the frame ends
...all without having any troubles of this kind as far as I can remember. Then again, did anyone ever verify that the PAL NES has the same problem? (I'm using an NTSC NES now while Years Behind was developed exclusively on PAL)
My bet is that this problem does not ever happens on PAL NES, but this would have to be confirmed. At least the DPCM-interferring-with-joypad-reads glitch does never happen on PAL NES.
You should also rememebr that the NTSC NES has 4 possible states possible at reset/power on while the PAL NES only have 1.
Quote:
You should also rememebr that the NTSC NES has 4 possible states possible at reset/power on while the PAL NES only have 1.
You've lost me there... didn't Blargg come to the opposite conclusion in
this post, which explained how there are 8 different power-up states on PAL? And the readme.txt in Blargg's synchronization package also talk of how the exact position of the writes "will change randomly each time you press reset".
This sure isn't a totally scientific test... but I've now played around with my game on my PAL console and no matter where I disable/enable rendering and no matter where my metasprites go, I get no corrupted sprites. So I'm prepared to accept your hypothesis of this hardware bug being fixed in the PAL NES as fact. That makes one more aspect where the PAL NES is superior to the NTSC one.
I've also realized that this OAM corruption bug totally kills my plan to have a really cool water effect in my game by disabling the screen/switching on the monochrome bit and updating almost the entire palette to get a noisy white scanline followed by turning on rendering/switching off the monochrome bit and starting a wavy effect loop. Because it wouldn't be worth much if all water would need to be placed at a point where game characters can't pass through it

Or alternatively, I guess I could go with the previously made statement that sprite flickering "characterizes NES games", and just let NTSC users suffer a flicker-fest that PAL users are spared of whenever there's water on a screen.
Oh PAL-centric innonence of my nesdev youth, how I want thee back... never realized back then that I was spoiled with more simplicities than just long vblank times!
Hmm, I still wonder whether disabling/enabling rendering only during dot 320-340 could magically avoid the bug. With Blargg's synchronization libraries, it seems like it shouldn't be too difficult to make the 1-(CPU) cycle store fall within that window...
Quote:
You've lost me there... didn't Blargg come to the opposite conclusion in this post, which explained how there are 8 different power-up states on PAL? And the readme.txt in Blargg's synchronization package also talk of how the exact position of the writes "will change randomly each time you press reset".
Oh I almost forgot about that. Blargg is probably right because he's way better than me at this kind of stuff. So yeah there is multiple alignments and I even proved it myself and I don't even remember it. Yeah. Just discard my post above.
I never really understood where those 8 alignments comes from.
PAL NES is technically superior, but unfortunately 99% of the game library was made for the NTSC NES which made their PAL version suck. Even European-developped games, such as Battletoads, runs better on NTSC because the music wasn't adapter to PAL properly.
Bananmos wrote:
I'm trying to have a black bar at the top instead of the bottom, and since I don't want the alternative dot crawl pattern of Battletoads, I have rendering enabled for 1 line just to prevent that.
I had the exact same problem. I could never fix the sprite glitching, so now I keep only the background disabled, and to mask sprites I put 9 high priority transparent sprites at the very top of the screen. This completely hides sprites for the first 17 scanlines, and doesn't mess with the dot crawl pattern.
Yes, having to waste 9 sprites is far from optimal, but it's not so bad when you use 8x16 sprites (you can still have more "sprite pixels" onscreen than you can with all 64 8x8 sprites), and is also better than what
Felix the Cat and
Alfred Chicken do, which wastes nearly a whole column of sprites and effectively reduces the sprites-per-scanline limit to 7.
Quote:
I wait for the previously set sprite#0 hit flag to clear to find end of vblank
With 9 sprites at the very top of the screen I can use the sprite overflow flag to detect the end of VBlank instead, since sprite 0 hits are harder to guarantee when you scroll both horizontally and vertically.
I'm sorry for not being able to help with the actual problem, but I wanted to share my experience with it. Since I couldn't solve the problem myself I just went with another solution that used more well documented behavior.
Thanks for the tip Tokumaru, but the main reason for my top black bar is not to hide sprites but to get some extra vblank time to do CHR animation. I guess the difficulty of this seriously makes me consider CHR-ROM instead though. But even with that my idea for the water effect still can't be done without turning screen off/on...
I realized my game's timing is a bit too unreliable to use Blarggs sync code at the moment, since some code takes more than a frame, which also means I can't always do DMA. Probably better to play around with Blarrg's example code instead, as this has already turned a seemingly simple task of adding more sprite animations to my game into a task of rewriting its code into a testbench...
Trying to move the point of disabling/enabling screen to always be around dot 330 did however show promises even without Blargg synchronization: Glitching is now totally independent of whether my metasprite intersects the black bar or not, and I get the following different glitch behaviors instead:
1: Sprites 2 and 3 have flickering chr patterns
2: Sprites 2 and 3 have flickering chr patterns, but less noticable than in case A
3: No sprite flickering, but palette color index $01 and $0E get changed in some frames
4: No sprite flickering, but palette color index $02 gets changed in some frames
5: No sprite flickering, but palette color index $0E gets changed in some frames
The glitch patterns I get seem to be a combination of reset state, and timing differences somehow trigerred by the "software reset" feature in my very simple in-game level editor in pause mode: Pressing SELECT turns screen off, copies a saved map in ROM to the normal RAM location and updates the PPU memory with it.
So at least I'm getting somewhere, as case 1 and 2 would actually be acceptable to have in a game - you would just have to make sure not to use those sprite indices. And with Blargg Synchronization it should probably be possible to squeeze the write into the "perfect" spot. I already have code to avoid using the first sprite index for any metasprites so changing that to start at index 4 is no biggie, even if it'd waste 4 sprites out of 64.
The other cases really confuse me though, as I don't understand how the palette entries could get corrupted unless written to? Seems to be yet another undocumented "feature" of the NES PPU... I have seen weird stuff like this happen if you write to $2007 while rendering is enabled, but I make sure to both lda $2002 to clear the latch, write #$08 to $2000 and #$00 to $2001 and double-write a constant chr pattern address to $2006 before doing any of the chr writes to $2007 in the black-bar area.
EDIT: I found the cause of the palette glitches. I had forgotten to set the scroll values before waiting for end of vblank, and since I write the palette in every vblank that happened to be what VADDR was pointing at in the first scanlines. As long as rendering is enabled, the PPU seems to read just the lower bits of the address and thus rendering a seemingly correct picture (albeit with shifted scroll values). But for some reason I do not yet understand it will corrupt the palette entries when you disable rendering and VADDR is pointing at the palette region.
After fixing that, only two reset states seem to exist: The one without any fliclkering, and the one where it only affects makes sprites 2 and 3 flicker. It might be possible to always get the first case deterministically by Blargg Synchronization, but it's probably not worth doing that for this alone. I'm happy to never use the first four sprites if it can let me freely do PPU updates anywhere in the screen. And it should allow me to do the planned water effect as well!
So from what I can tell so far it seems that the easier guidelines for avoiding this hardware quirk are: Make sure disabling/enabling the screen happens around dot 330, and avoid using sprites 2 and 3.
Bananmos wrote:
Thanks for the tip Tokumaru, but the main reason for my top black bar is not to hide sprites but to get some extra vblank time to do CHR animation. I guess the difficulty of this seriously makes me consider CHR-ROM instead though.
Yeah, my problem was EXACTLY the same as yours. My blank bar was meant for hiding scrolling glitches AND for extra VRAM updates, but it was so much trouble that I decided to cut back on the CHR animations (not as many tiles animate each frame). The possibility of using the MMC3 was indeed really tempting.
Quote:
But even with that my idea for the water effect still can't be done without turning screen off/on...
Yeah, that's a tough one.
Quote:
The other cases really confuse me though, as I don't understand how the palette entries could get corrupted unless written to?
I'm very surprised by this too! Never heard of this!
Bananmos wrote:
Quote:
You should also rememebr that the NTSC NES has 4 possible states possible at reset/power on while the PAL NES only have 1.
You've lost me there... didn't Blargg come to the opposite conclusion in
this post, which explained how there are 8 different power-up states on PAL?
Well, farther down in that thread thread I do
conclude 8 different PAL synchronizations at power. Due to the frame length, a given PPU dot in the frame (beginning of VBL, first pixel, etc.) always falls at one of the same two points, half a CPU cycle apart, on a CPU cycle, for a given power up/reset. Successive PPU cycles rotate through all possible positions within a CPU cycle, but those of particular dots in the frame (VBL begin, first pixel, etc.) are always on one of these two for a given power/reset. There are 8 possible pairs of these half-cycle-spaced points, so 8 synchronizations.
Speaking of different synchronizations, when can we expect an emulator author to step up and support them?
Quote:
The other cases really confuse me though, as I don't understand how the palette entries could get corrupted unless written to?
Remember the palette is DRAM. If you use forced blanking it's content will be lost after awhile. Same goes with OAM.
Quote:
I realized my game's timing is a bit too unreliable to use Blarggs sync code at the moment, since some code takes more than a frame, which also means I can't always do DMA.
You could go Kirby's adventure route and double-buffer your OAMs. But I admit that if you don't use SRAM it's quite wasteful.
Quote:
Remember the palette is DRAM. If you use forced blanking it's content will be lost after awhile. Same goes with OAM.
Yep, I know the contents degrade - that's why I'm always rewriting the palette in vblank even though it's quite a bit of wasted cycles. Second reason is of course the planned water effect would require it anyhow, and it generally simplifies things.
Anyway, like I said in my post-edit the issue was something else entirely, and I now have a top chr-uploading blank bar and no sprite flicker as long as I don't use sprites 2 and 3 which is good enough for my purposes. Though I'm still confused as to how disabling rendering while VADDR points to the palette corrupts it. But I guess the work of reverse engineering the PPU from the die will give us the answers some sunny day...
I remember going over this ages ago, and remember that it was only the first
four six sprites that actually triggers the OAM corruption, and it's only when those specific sprites are intersecting the scanline where the rendering is shut off.
If you keep sprites
0, 1, 2, and 3 0 through 5 away from where you turn the rendering off, you should avoid the OAM corruption all together, unless I've misinterpreted the information.
Edit:
Here is my post on the matter, and it's the first six sprites, not the first four.
Quote:
I remember going over this ages ago, and remember that it was only the first four six sprites that actually triggers the OAM corruption, and it's only when those specific sprites are intersecting the scanline where the rendering is shut off.
I tried moving sprites 1-4 to the top so they intersect the black bar where I update CHR, and it doesn't seem to give me any OAM corruption (except, I assume, for sprites 1 and 2 which are hidden behind the bar. So I still say turning screen off around dot 330 is "safe enough". But of course, you should take an empirical test for what it is and always try your code on the real target system before making any conclusions of how well it really works